Warning 注意,在开始之前,我们已经假定你已经拥有了一个Vsphere数据中心!如果你还没有自己的数据中心,可以遵循 Vsphere 的文档,租用场地,来建设自己的数据中心。
注意,这篇文章不讨论如何建设 Vsphere 数据中心!
在这篇文章写作时,我的朋友 EdgeNeko 和 Codgician 给了我极大的支持!没有他们的帮助,我是不可能独自搞定这件事的。我也从他们那里得到了大量知识。非常感谢他们!
在我们一起折腾的时候,他们也写了一些笔记。在允许的情况下,我引用了一些他们的笔记,包括:Linux下从零开始配置一个Nvidia Grid客户机。如果愿意,我也非常鼓励你去关注这两位大佬,他们都是计算领域的顶级高手。

参考资料
EdgeNeko的博客 https://edgeneko.aiursoft.cn/2023/04/17/NvidiaGridGuestConfiguration/
Google 提供的 NVIDIA Grid Guest 驱动下载。在你没有 License 的情况下,这里可能可以搞到 Guest 驱动。 https://cloud.google.com/compute/docs/gpus/grid-drivers-table
NVIDIA 官方的 GRID 安装指南。这里几乎覆盖了所有场景下 NVIDIA 的部署问题。 https://docs.nvidia.com/grid/latest/grid-software-quick-start-guide/index.html
这里是 VMware 的官方文档,详细介绍了正统的在一台 ESXI 主机上安装 vGPU,并享受到图形化的 Linux 桌面的方法。 https://docs.vmware.com/en/VMware-Horizon/2212/linux-desktops-setup/
这篇博客介绍了如何使用 VMware 自带的 LIfecycle Manager 功能来对所有主机进行驱动管理。 https://blog.kinamo.be/en/installing-nvidia-vgpu-driver-for-esxi-through-vcenter-lifecycle-manager/
这篇博客编写的较早,它也详细介绍了硬件加速的图形虚拟机在 VMware Horizon 里的配置方法。它的内容可能不太合适,但是引用的数据非常详尽。 https://techzone.vmware.com/resource/deploying-hardware-accelerated-graphics-vmware-horizon-7
为什么要做这件事?
众所周知,AI 就是未来。而 AI 对算力要求巨大无比。传统的 CPU 计算几乎无法满足 AI 计算的需求。
而目前流行的解决方法就是使用GPU进行AI计算。相对于CPU,GPU具有更高的并行计算能力和更多的计算单元,可以大大加速大规模AI计算任务。此外,GPU还支持各种专门为AI计算开发的库和框架,例如CUDA、CuDNN、TensorFlow等,这些库和框架可使AI计算更高效、更易于实现。
除了GPU,目前还有一些其他的解决方案,例如用TPU(Google的自定义AI计算加速器)进行AI计算。但是目前来看,GPU在AI计算中是最广泛使用的解决方案之一,也是目前拥有最成熟支持生态系统的解决方案之一。
CUDA?
相对于传统的CPU架构,CUDA架构更专注于通用并行计算,因此有时被称为通用GPU(GPGPU)。CUDA可以将GPU转变为高效的并行计算设备,从而加速许多科学、工程和大数据分析应用程序。CUDA是NVIDIA公司开发的一种基于C/C++编程模型的高性能并行计算框架,它基于GPU硬件的特点进行了优化,提供了许多与GPU硬件紧密结合的编程语言扩展、运行库、开发工具等。
在GPU上执行并行计算可以大大提高计算效率,CUDA利用GPU的大规模并行性、高带宽内存等特点极大地提升了科学计算和深度学习等应用程序的性能,使得其具有更好的计算效率和运行速度。
虽然CUDA是一种通用的并行计算框架,但并不是所有应用程序都能够从CUDA带来性能上的提升
为什么不能使用消费者显卡,例如 NVIDIA® GeForce RTX™ 4090?
要使用 GPU 进行计算,首先我们就需要购买专业的计算卡而不是消费者的Geforce显卡。这是因为专业的计算卡和消费者级别的显卡在设计上有很大的差异。专业的计算卡,如Nvidia Tesla等,是专门为高性能计算而设计的,具有更多的计算单元以及更多的显存,在数据处理和计算方面也比消费者级别显卡更加高效。此外,专业计算卡通常支持双精度计算(double-precision calculation),这是一种更为精确的计算模式,消费者显卡则只支持单精度计算(single-precision calculation)。

专业的计算卡在支持高性能计算方面还具有许多其他的优势。其中之一就是提供GPU虚拟化技术(vGPU)。vGPU允许多个虚拟机共享同一块物理计算卡,每个虚拟机可以获得独立的GPU计算性能,可以有效地提高计算资源的利用率和效率。这项技术对于云计算、虚拟桌面和远程图形应用程序等方面非常有用。其中,sdev(Shared Device)技术是一种常用的GPU虚拟化技术,它允许虚拟机共享同一块物理GPU,并在不同的物理机上进行迁移。sdev技术利用了PCIe设备直接分配的技术,将物理GPU划分为多个虚拟设备,并将它们分配给不同的虚拟机。在虚拟机迁移过程中,所有的虚拟设备都可以迁移到新的物理机上,以实现虚拟机的无缝迁移。这就使得GPU虚拟化技术更加具有可扩展性和可移植性。
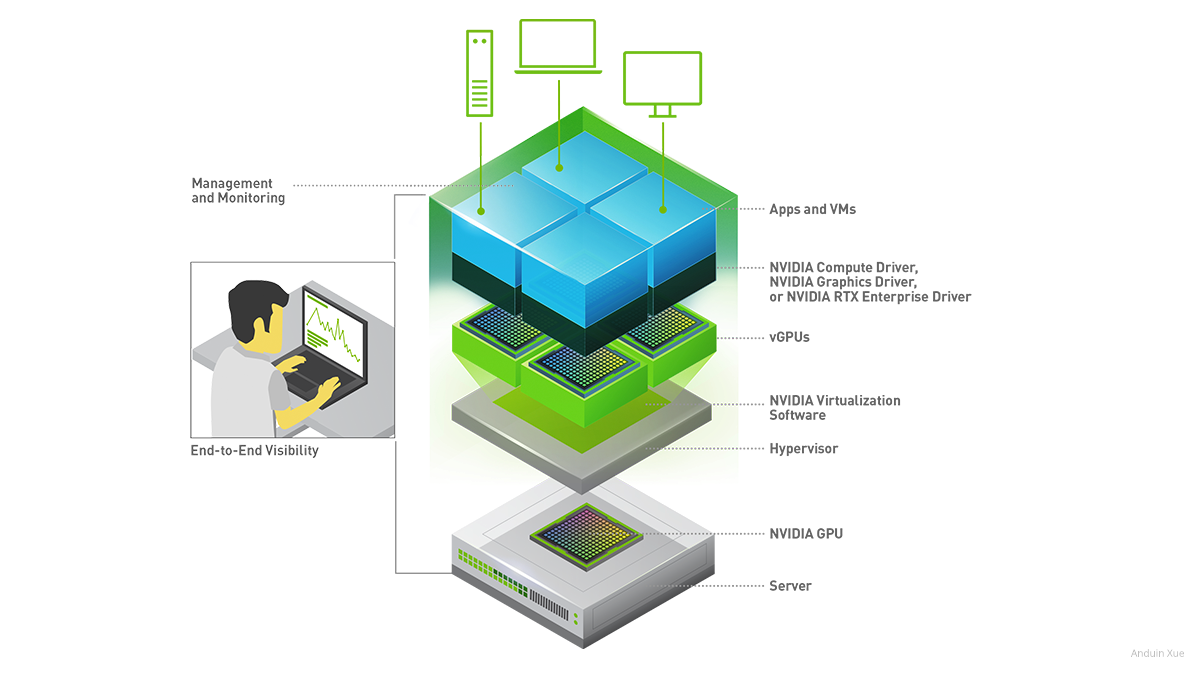
此外,专业的计算卡还可以提供GRID功能。GRID是Nvidia公司推出的一个面向云端虚拟化的解决方案,它通过GPU硬件加速来提供更高效的图形处理和计算性能。使用GRID技术可以大大提高用户在虚拟桌面和云端应用程序上的图形表现和计算性能,提高用户的工作效率。因此,企业、科研机构和云计算服务提供商都可以从GRID技术中受益。
另外,专业的计算卡还具备更好的稳定性和可靠性,它们能够保持高强度的运行状态数日甚至数月,具有更长的寿命和更好的抗干扰和抗震动性能,适合于长时间高负载的计算任务,而消费者显卡则适合更一般的游戏和图形处理工作。
FPGA ?
除了GPU和TPU,FPGA(Field-Programmable Gate Array)也是一种常用的AI计算加速器。FPGA是一种可以通过编程改变电路功能的硬件电路芯片,可用于定制化的硬件加速器设计。相对于GPU和TPU,FPGA具有更高度的灵活性和可定制性,可根据应用程序和算法的特定需求进行优化。同时,FPGA的功耗和延迟也相对较低。然而,FPGA的开发成本和难度很高,需要掌握硬件描述语言和电路设计知识,因此使用GPU和TPU进行AI计算仍是目前较为普遍的选择。
在这里不深入讨论 FPGA。
SR IOV ?
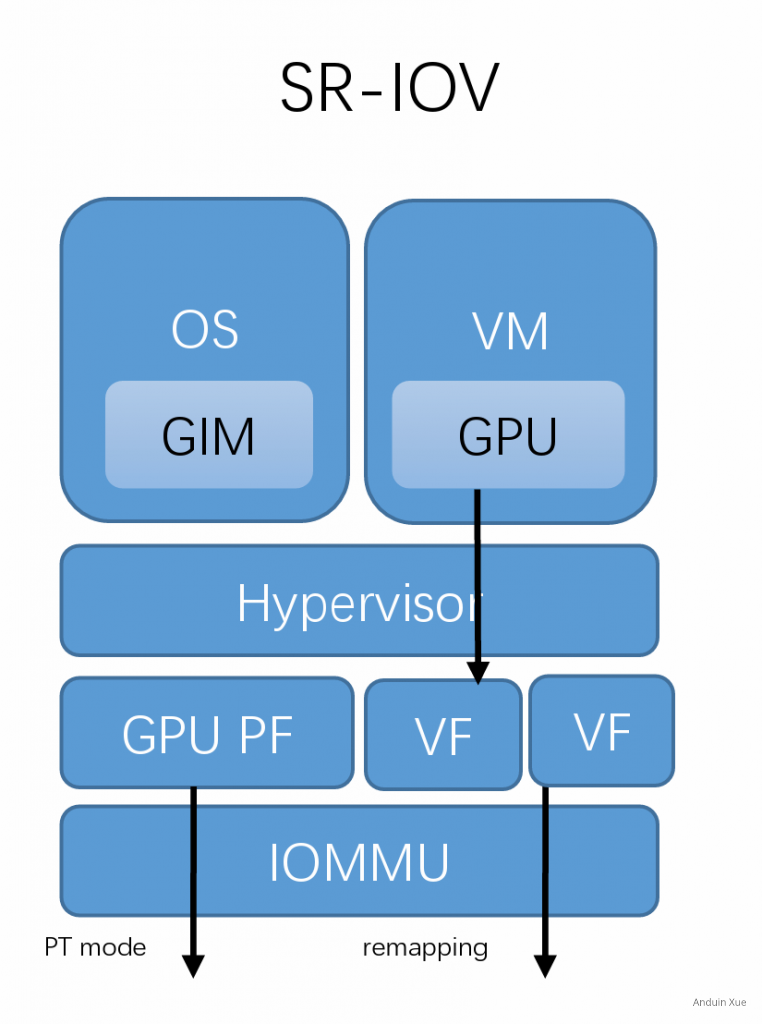
SR-IOV(Single Root I/O Virtualization)是另一种硬件虚拟化技术,与GPU虚拟化技术的sdev技术类似,它也能够将一个物理设备分成多个虚拟设备,以供多个虚拟机使用。但SR-IOV技术主要用于网络设备上,用于实现高效的网络虚拟化。相较于GPU虚拟化技术中的sdev技术,SR-IOV技术更加注重I/O虚拟化,而不是GPU计算虚拟化。所以,两者针对的应用场景有所不同。
SR-IOV技术需要硬件支持,所以只有在硬件平台支持的情况下才能使用。SR-IOV设备使用VF(Virtual Function)和PF(Physical Function)两种功能来实现虚拟化。PF是实际的物理设备,而VF则是通过SR-IOV技术虚拟出的多个设备。VF之间是独立的,它们能够直接访问PF和物理网络,实现高效的数据传输。
使用了SR-IOV技术虚拟化的GPU设备,在尝试将虚拟机迁移到另一台物理机时,可能会遇到一些困难。这是因为SR-IOV技术使用的VF(Virtual Function)仅由单个物理设备(PF)提供,VF不能够直接从一个物理设备迁移到另一个物理设备。另外,在使用SR-IOV技术时,虚拟机与VF之间的映射关系是在虚拟化过程中预定义的,这就限制了在迁移过程中的灵活性。
因此,如果需要对使用SR-IOV技术的虚拟机进行迁移操作,可能需要额外的工作。SR-IOV 的话看起来是直接调 GPU 硬件上的 VF,live migration 本质上是断开再重连。例如在目标物理机上预配置与源物理机相同的VF映射关系,并确保在迁移过程中保持VF与物理设备之间的对应关系,以确保迁移后虚拟机能够正确使用GPU资源。
可以参考使用 SR IOV 的迁移时可能产生的延迟图表:
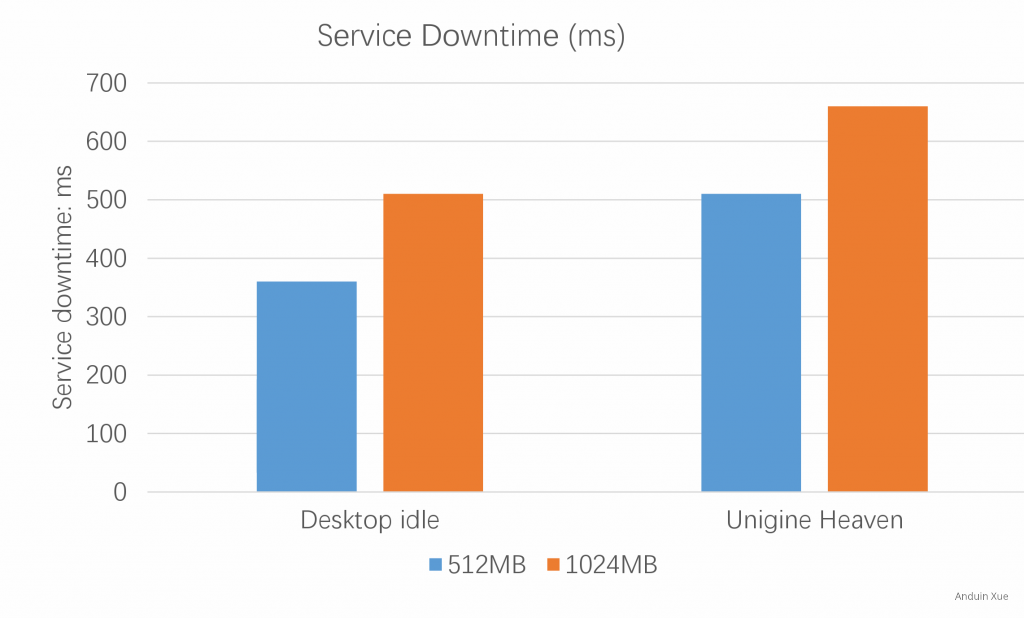
总之,虚拟化技术能够带来很多好处,但是也带来了一些挑战,特别是在处理高性能计算场景。要想使虚拟化技术更加灵活和可用,需要在技术和工程实践层面不断地推进和创新。
最终选择的形态:mdev
mdev(Mediated Device)是一种软件虚拟化技术,能够将物理设备虚拟化为多个虚拟设备,以供多个虚拟机使用。与SR-IOV技术类似,mdev也需要硬件平台的支持,但是它不需要物理设备直接支持SR-IOV。
在实现上,mdev通过在主机内核中构建虚拟设备驱动程序来实现对物理设备的虚拟化。主机内核中的虚拟驱动程序可以让多个虚拟机直接访问物理设备,而不会发生冲突或干扰。相较于SR-IOV技术,mdev技术在虚拟设备之间的映射关系更加灵活,这使得将虚拟机从一台物理机迁移到另一台物理机时更加容易。
NVIDIA vGPU 技术在底层使用了 mdev 技术来实现 GPU 资源的虚拟化和分配。所以非常容易将 vGPU 在物理硬件之间迁移。
(不得不说,如图所示,这张图我看着就感觉非常容易在设备之间迁移)
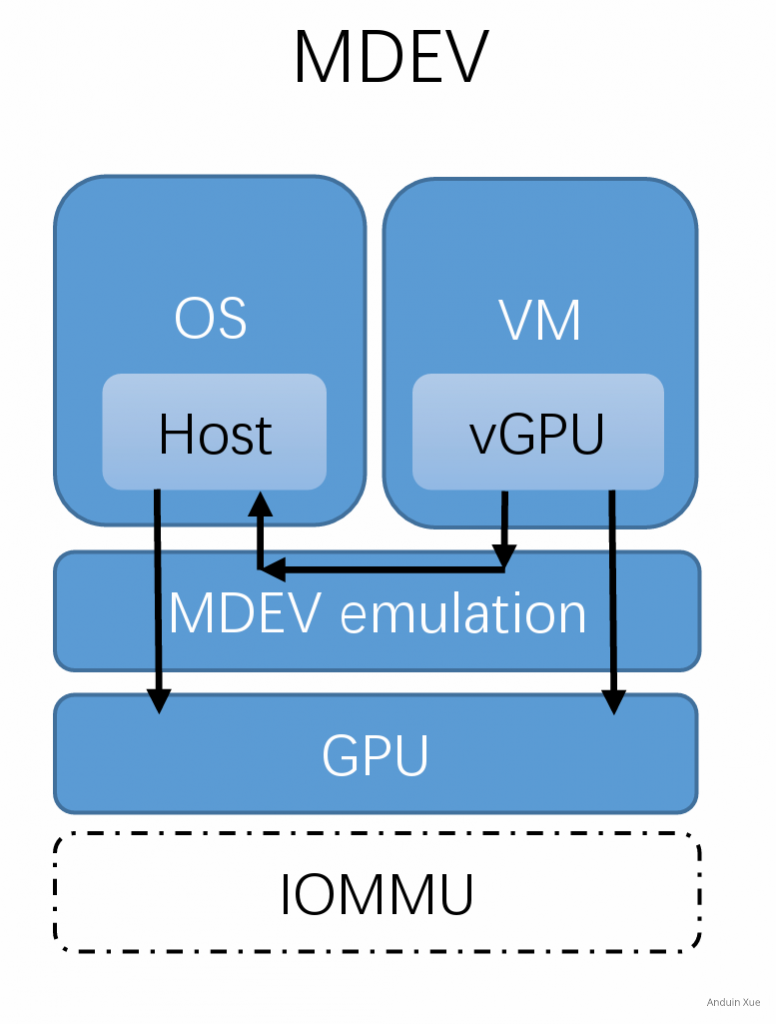
mdev 技术不仅仅限于 GPU 设备,它也可以用于其他类型的 PCIe 设备,例如网络接口卡(NIC)。mdev 是一个通用的设备虚拟化框架,旨在为各种类型的设备提供硬件资源划分和虚拟化功能。对于支持 mdev 的设备,它们的驱动程序可以利用 mdev 框架实现资源的虚拟化和分配,从而使多个虚拟机或容器能够共享物理设备的资源。mdev 技术在网络虚拟化场景中也非常有用,例如在数据中心和云计算环境中。通过将物理网络接口卡的资源划分为多个虚拟设备,可以降低资源消耗、提高资源利用率,并简化网络管理。总之,mdev 技术适用于多种 PCIe 设备,包括但不限于 GPU 和网络接口卡。设备驱动程序可以利用 mdev 框架为虚拟化环境提供硬件资源虚拟化和共享功能。
购买和插入计算卡
购买
我购买的是 Nvidia P40。在开始之前,我使用 P4 进行了尝试。P40的价格大约在每块1100元。而 P4 则非常便宜,只需要大约 400 元。建议在闲鱼购买。

在购买之前,你必需思考:你需要的可能不是一块计算卡!只购买一块计算卡会导致只有一台主机有 vGPU 功能,而你的 vGPU 仍然享受不到迁移能力!这导致你仍然会失去 VMware 的 DRS (动态资源平衡)、DPM(动态电源管控)和 HA(高可用性)等能力!我仍然建议使用对称计算,也就是对于一个集群,里面有几台主机,就购买几块计算卡!
散热
注意!P40 上面没有散热风扇!!!不要把它安装在消费者设备上!!!这是考虑到 P40 非常依赖服务器的风道进行散热!

例如,我采用的服务器是 PowerEdge R730 Rack Server。它可以完美的让机器的风吹向 P40。

如果你要在消费者设备上安装计算卡,你必须自己 3D 打印一个风扇!
申请 License
申请 NVIDIA 试用
要想在Nvidia VGPU进行Cuda计算或者输出显示,必须安装NVIDIA Grid驱动,但是这个驱动是要钱的,并且如果你是个人非常难以购买。
注意:这个驱动并非只要搞到二进制就完事儿了。计算卡在安装驱动后,必须每隔一段时间就要去申请 License。所以它更像是一个生命周期极短的 KMS 激活。一旦激活服务器认为你的授权已经过期,就会立刻锁住计算卡。
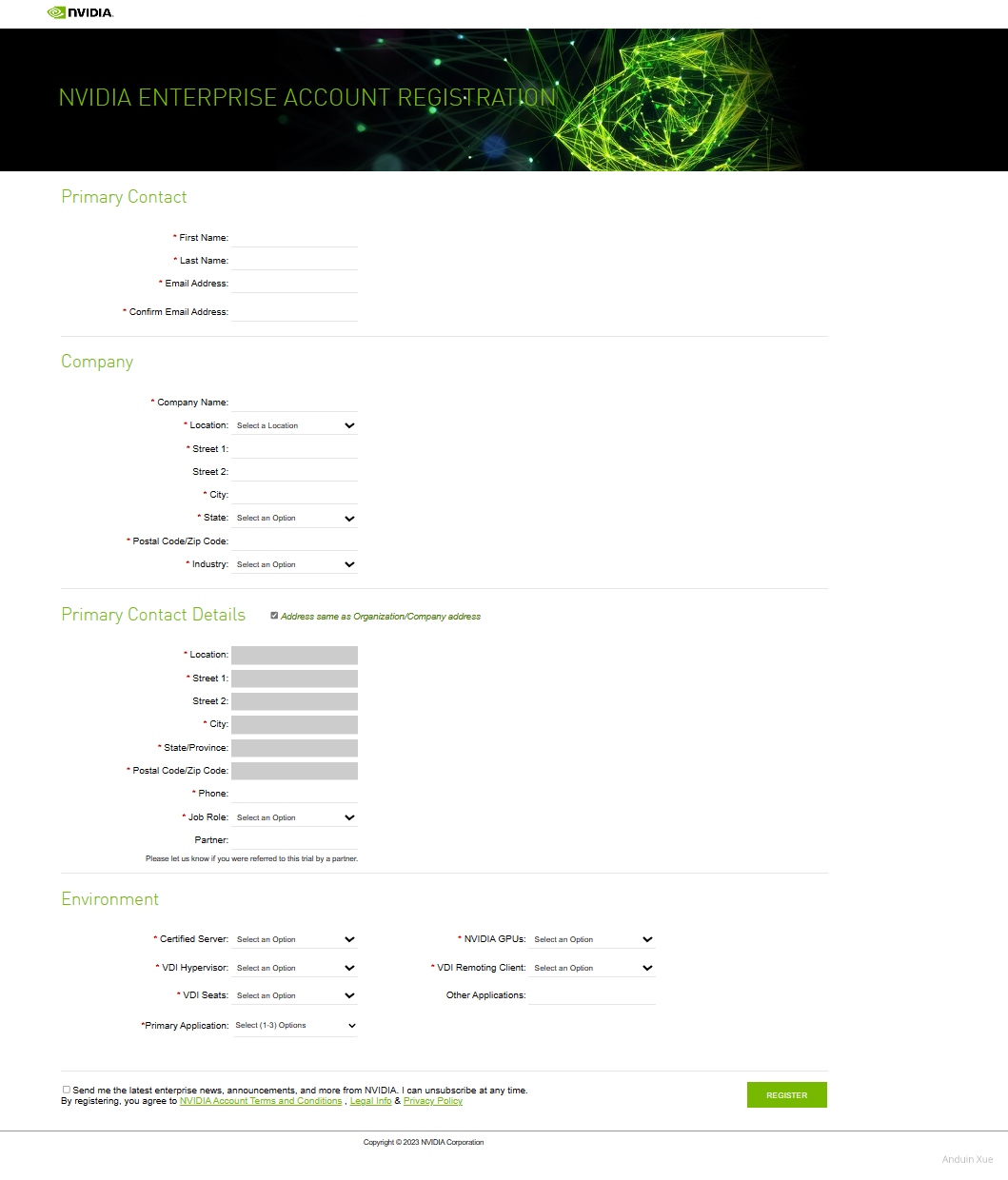
要申请评估,打开NVIDIA Vgpu评估中心, 选择Rigister For Trial, 邮箱填写参考下方提示,其它信息按真实填写即可。

在这里详细填写你的公司的信息。注意:一定要填写一家真实公司的信息!Nvidia 会非常严格的禁止个人用户申请 vGPU License!不要使用个人邮箱!
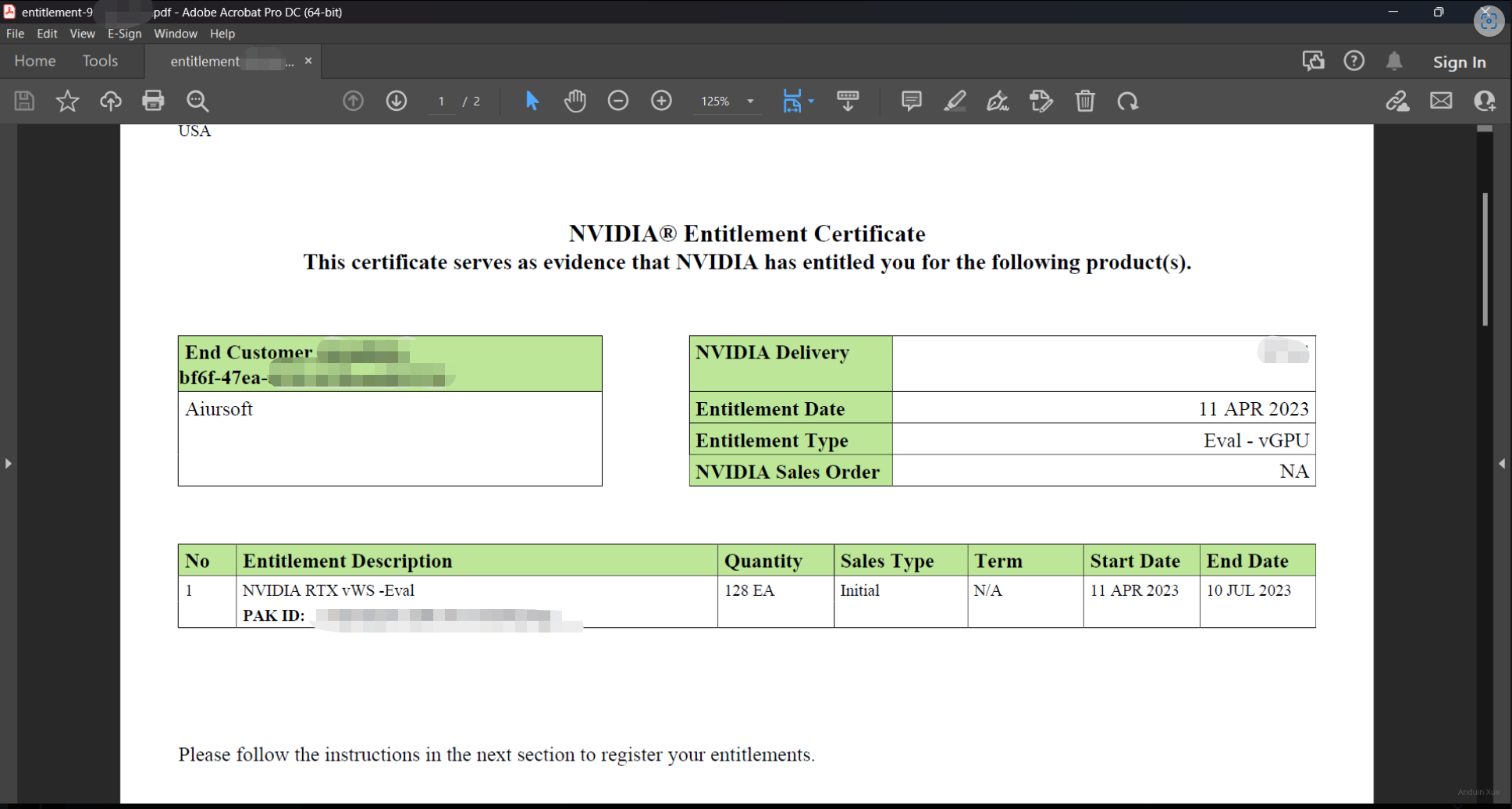
在申请完成后,等待一段时间(数分钟到数天),如果一切顺利,会收到一封确认Email。
创建 License Server
前往NVIDIA 的 Dashbord:https://nvid.nvidia.com/dashboard/#/dashboard 登录你申请时使用的 Email。
- 选择
License Server, 点击Create Server - 填写名称和描述,勾选
Express CLS Installation, 选择Next
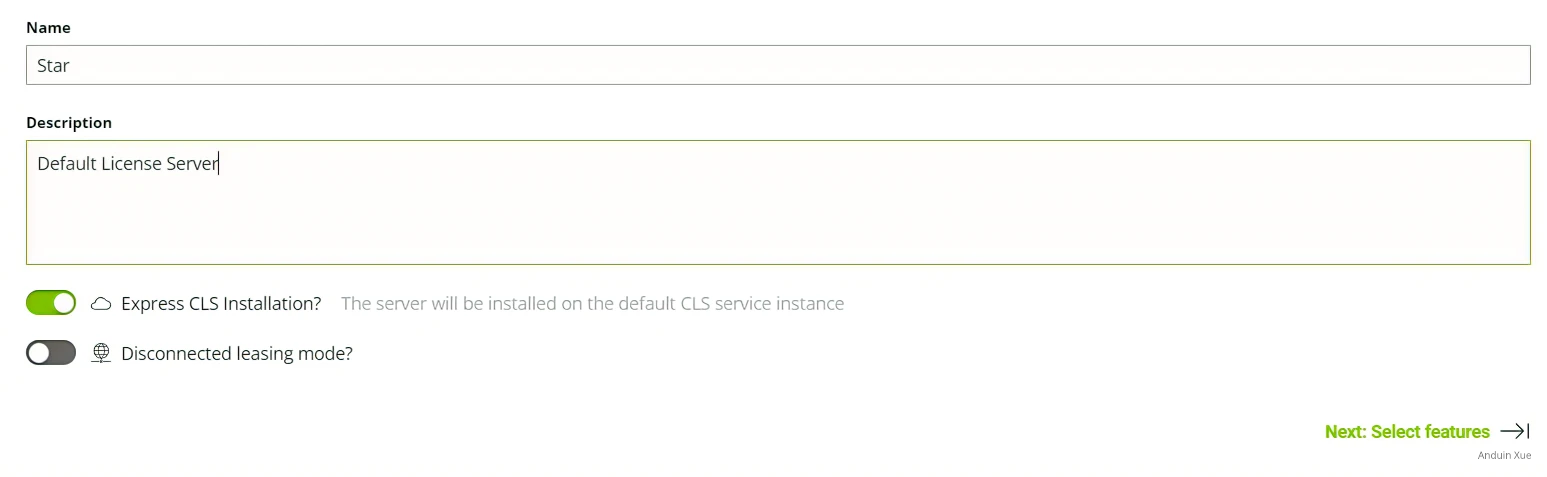
为服务器分配许可证,我分别分配了16个vWs许可证与16个vApp许可证到许可服务器中,你可以按照你的部署规模调整部署数量。
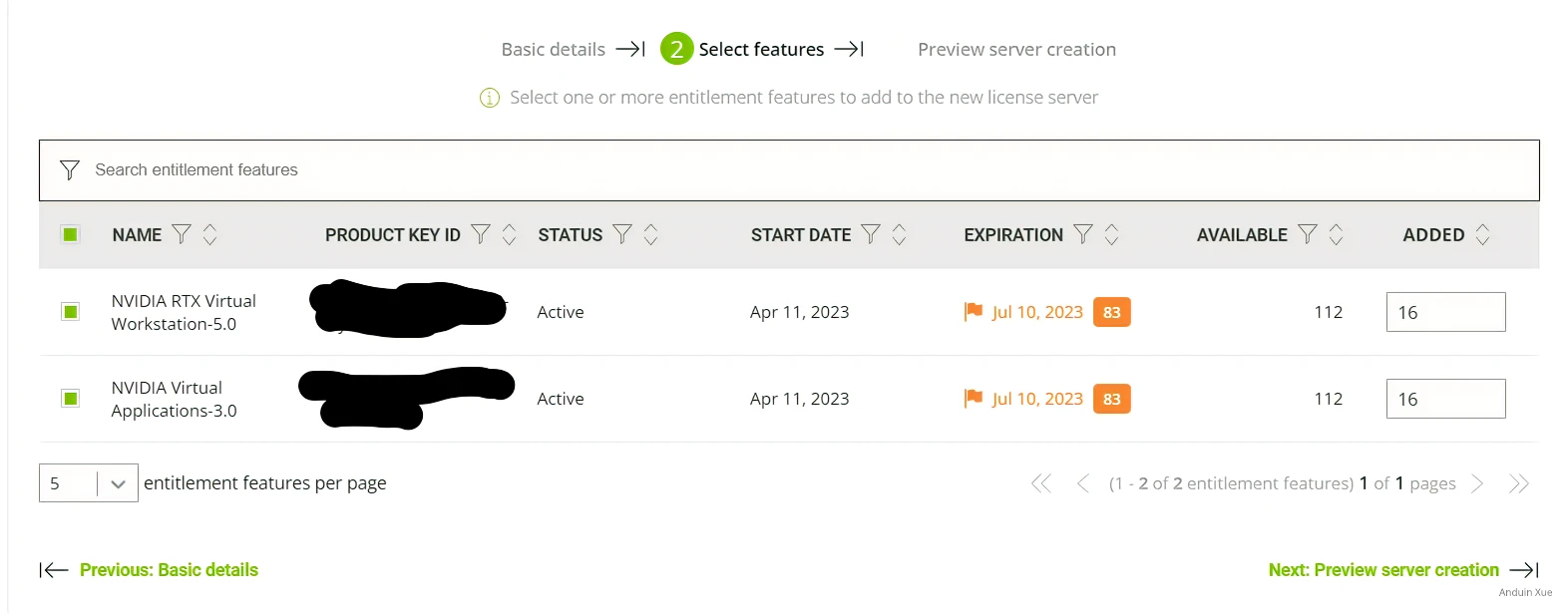
完成后 Next,然后 Create Server 即可
左侧选择Server Instances, 然后在 Actions 中选择 Generate Client Configuration Token,选择你刚才创建的许可服务器,然后 Download,这个文件将在之后为服务器配置许可时用到。
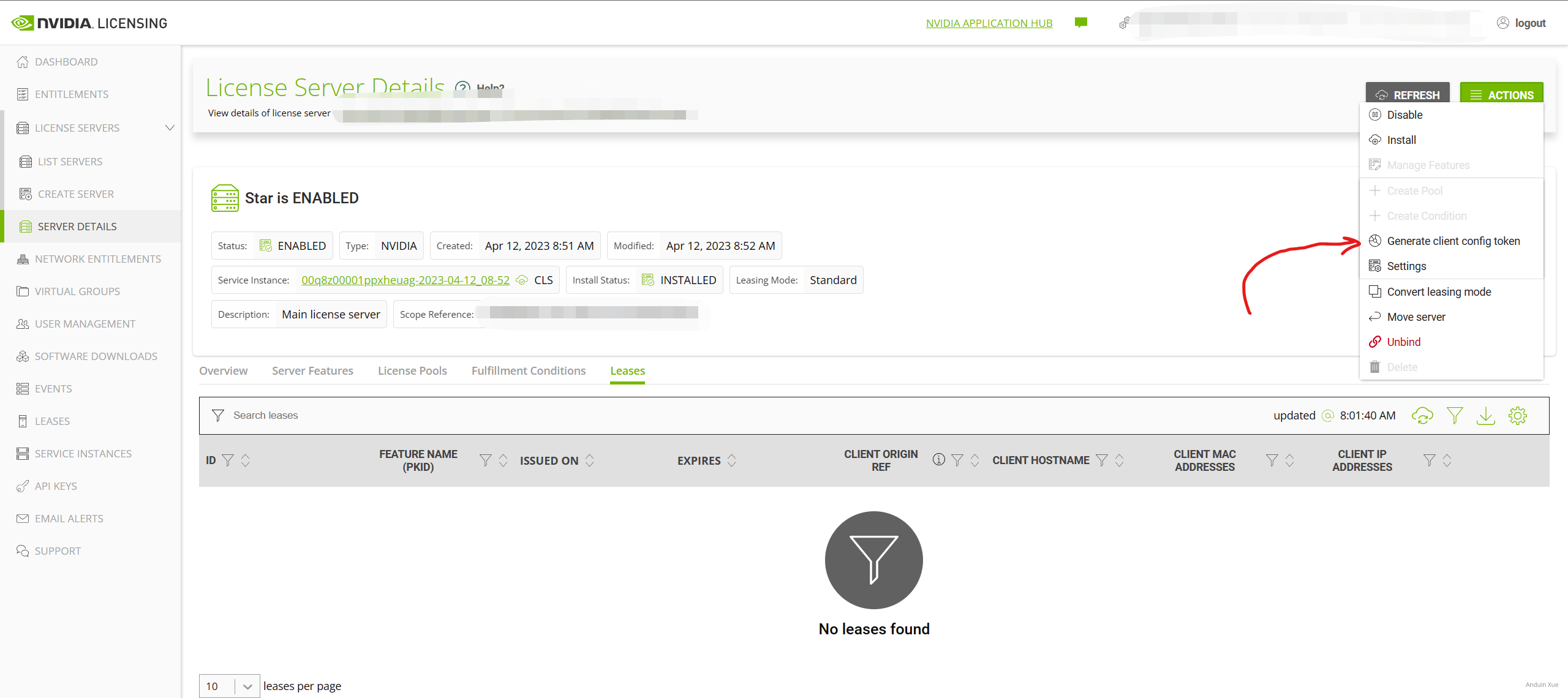
为主机安装驱动
下载驱动
首先在 NVIDIA 官网下载驱动。筛选 Product Version 为最新的大版本,例如 15 。注意选择适合你的 Vsphere 的版本。我还在使用 Vsphere 7.0,这里使用这个驱动。
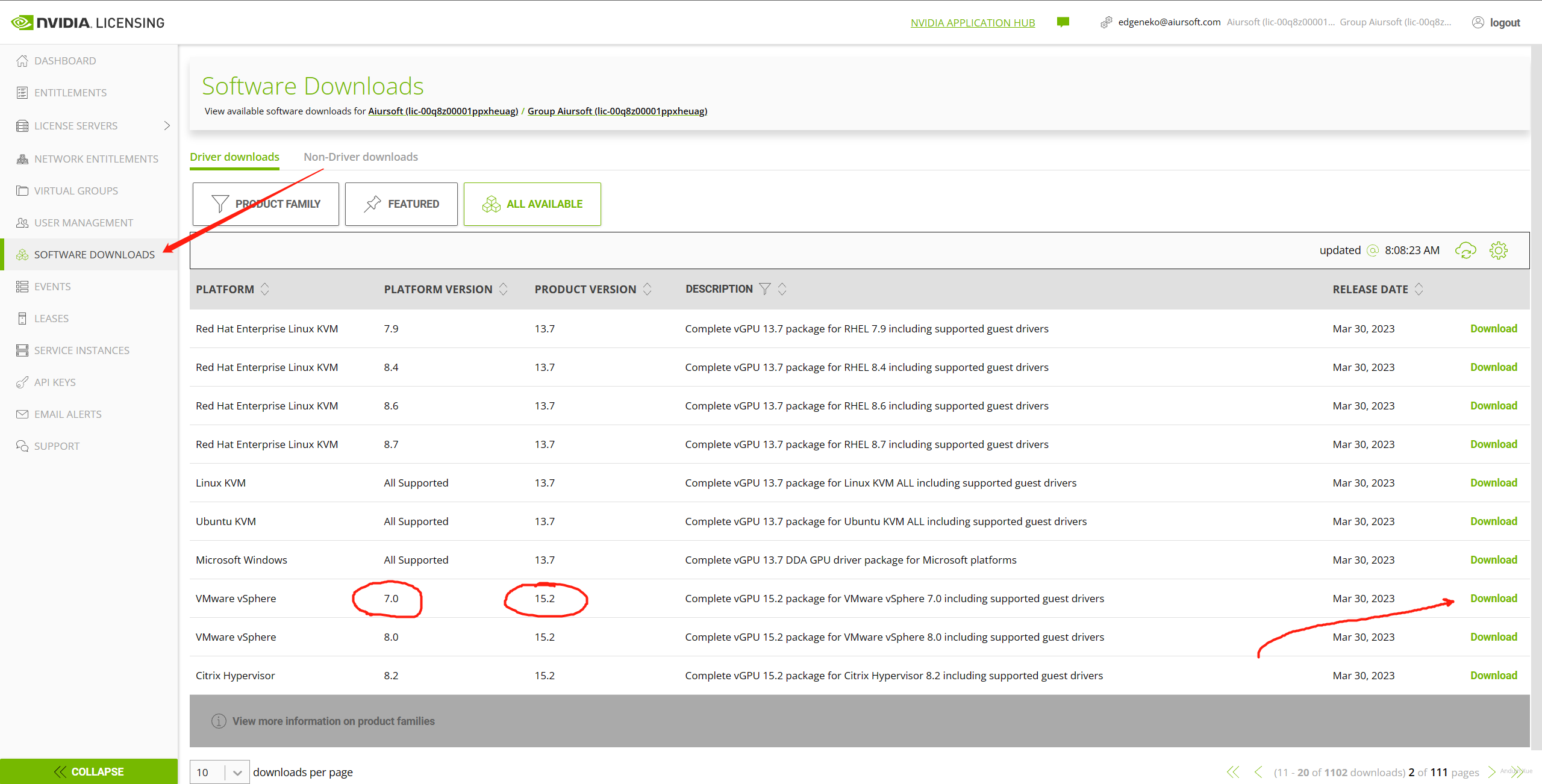
注意:这个驱动很大。可能有 2GB 以上。 注意:不要把这个驱动发到互联网上供所有人下载!
在这里,你将会看到这两个压缩文件。它们都是必需的!
NVD-VGPU-702_525.105.14-1OEM.702.0.0.17630552_21514677.zip
nvd-gpu-mgmt-daemon_525.105.14-0.0.0000_21514245.zip
将驱动上传到 VMware Lifecycle Manager
我推荐使用 VMware Lifecycle Manager 来安装驱动。打开 VCenter Server,打开 Lifecycle Manager,查看现有的驱动配置。按名称筛选 Nvidia:
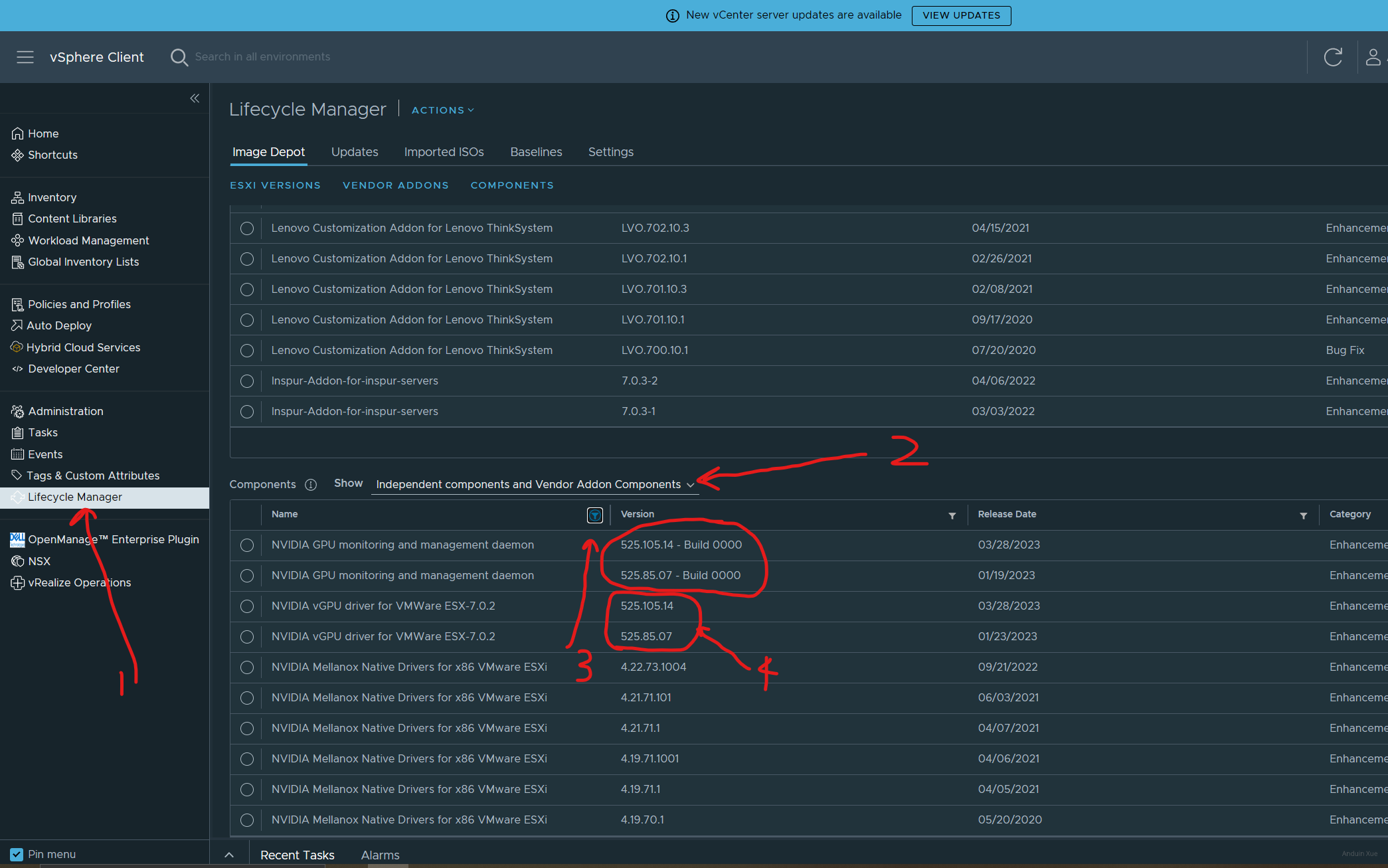
如图所示,VMware Lifecycle Manager 已经识别到了驱动 525.105.14。如果这里没有最新版驱动,你需要将驱动上传。
选择 Actions -> Import Updates,将驱动上传。
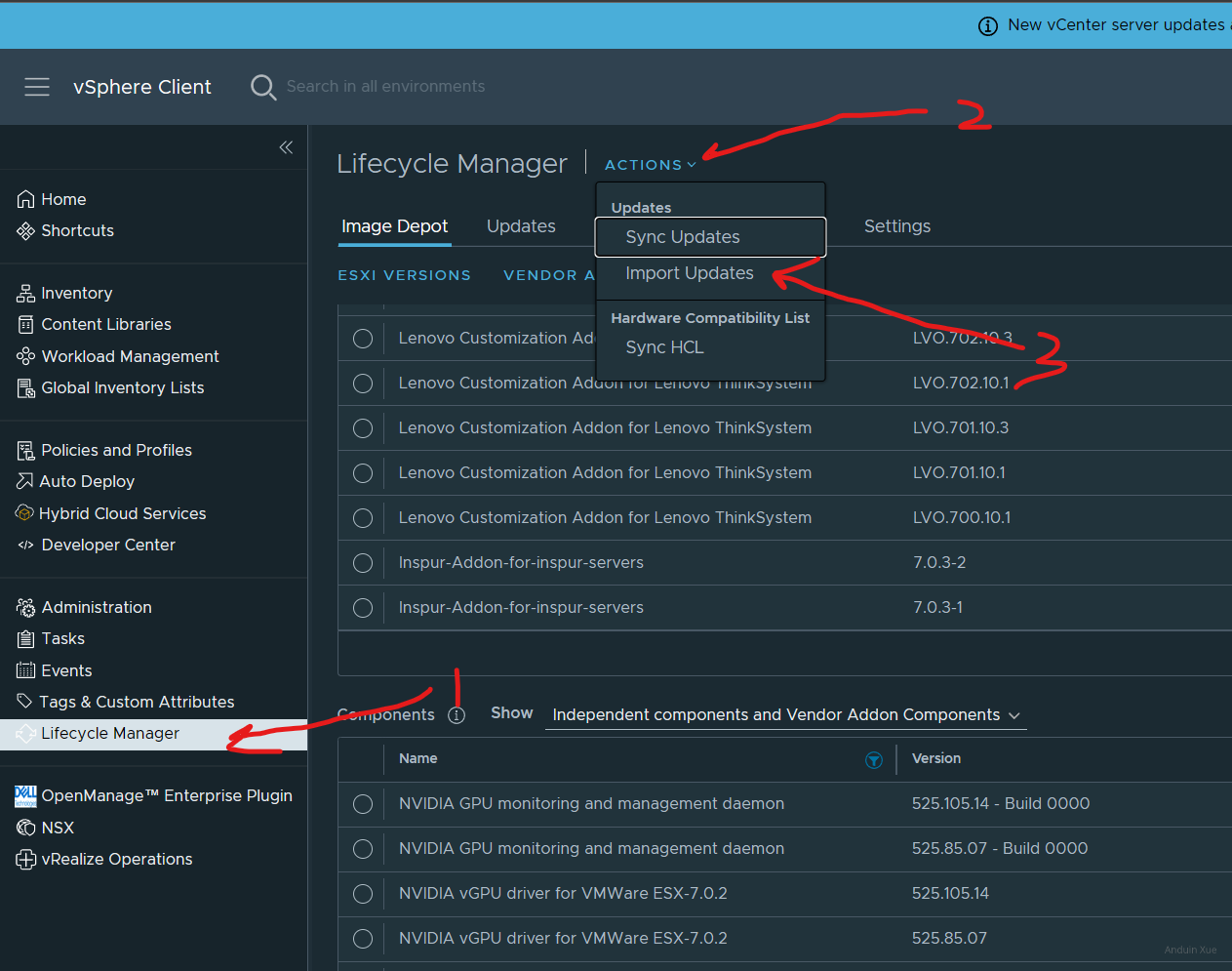
一般来说,上传整个 zip 文件后,可能需要等待数分钟,让 VCenter 去 Sync update。如果存在问题,可以试图上传里面附带的 metadata.zip。
在上传完成后,修改计算集群的 Image 设置,增加 Grid 驱动。
之后你需要对所有主机进行重装系统。如果你的 Vsphere 配置正确,这不会造成 downtime。可以观看我录制的视频:
(如果视频不能播放,请点击:这里)
在安装完成后,在主机的配置部分,选择 Graphics,即可看到计算卡。
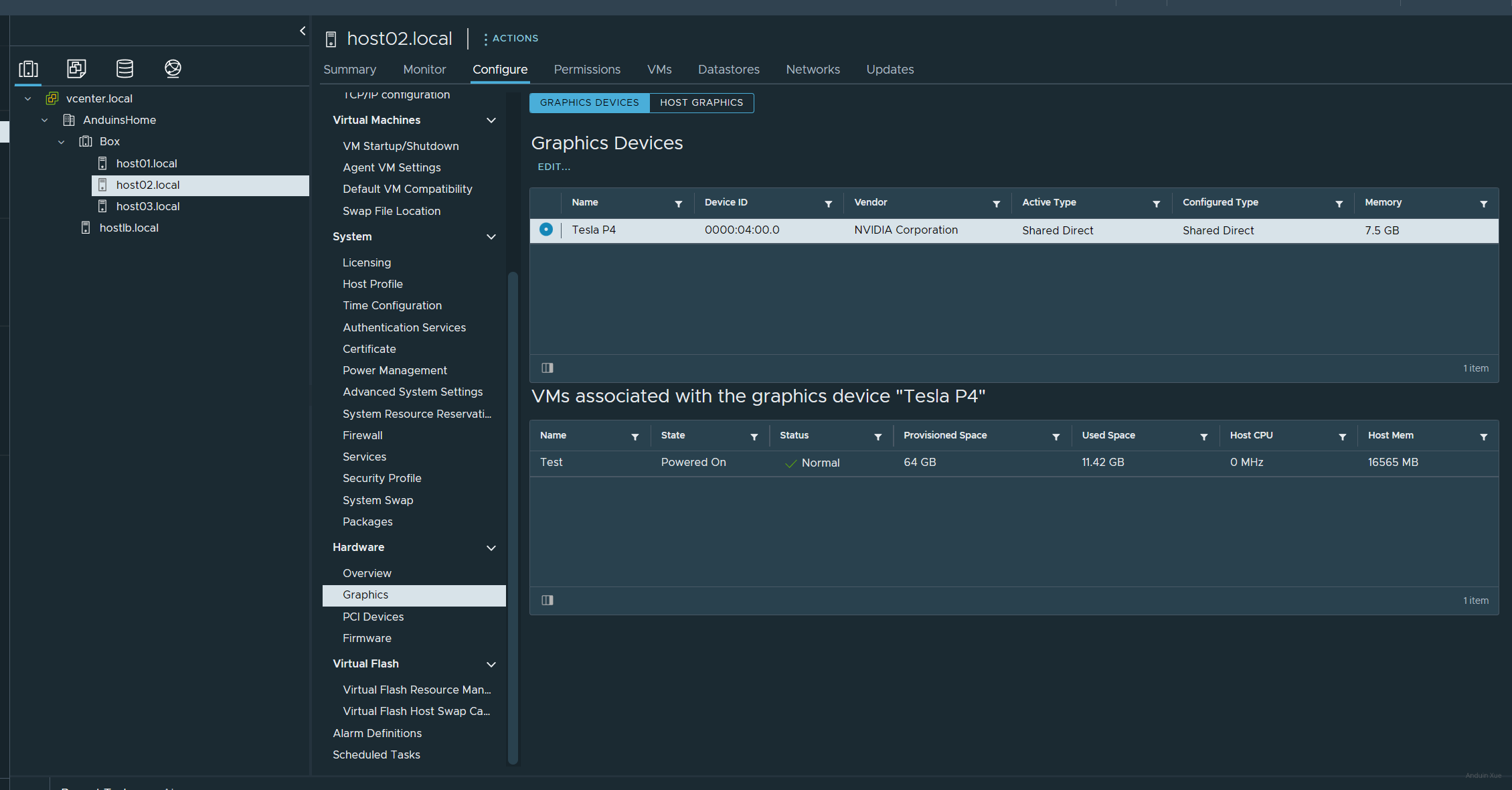
在这里,你将会看到选项:
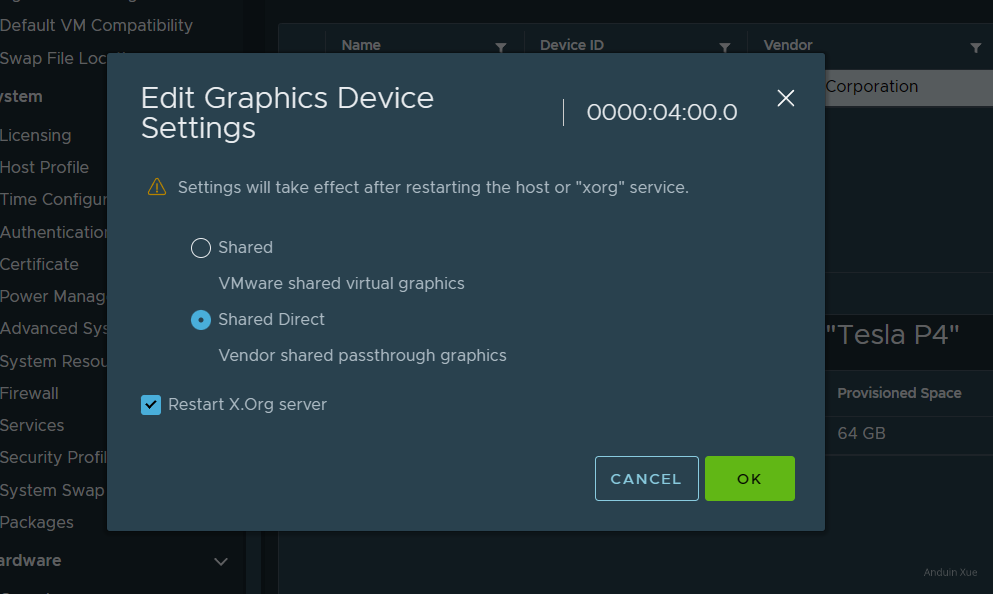
一定要选择后者 shared direct。
前者是跟 vm workstation 的那种半虚拟化显卡加速一样,后者才是 GRID/MxGPU
将vGPU分配给虚拟机
注意,在开始之前,建议关闭 Cluster 里的 DRS 和 DPM 功能!开启 vGPU 会导致虚拟机暂时无法被迁移。但是,VCenter 可能仍然会尝试迁移这台虚拟机或 DPM 将主机关机,然后发现遇到错误,最后无限死锁。
决策分配给虚拟机哪个vGPU
首先将虚拟机迁移到拥有 GPU 资源的主机上。如果你的整个集群的所有主机都有 GPU,则不需要做这一步。
在VCenter Server中,为你的虚拟机增加一个虚拟 PCI 设备。选择穿透 NVIDIA GRID vGPU。
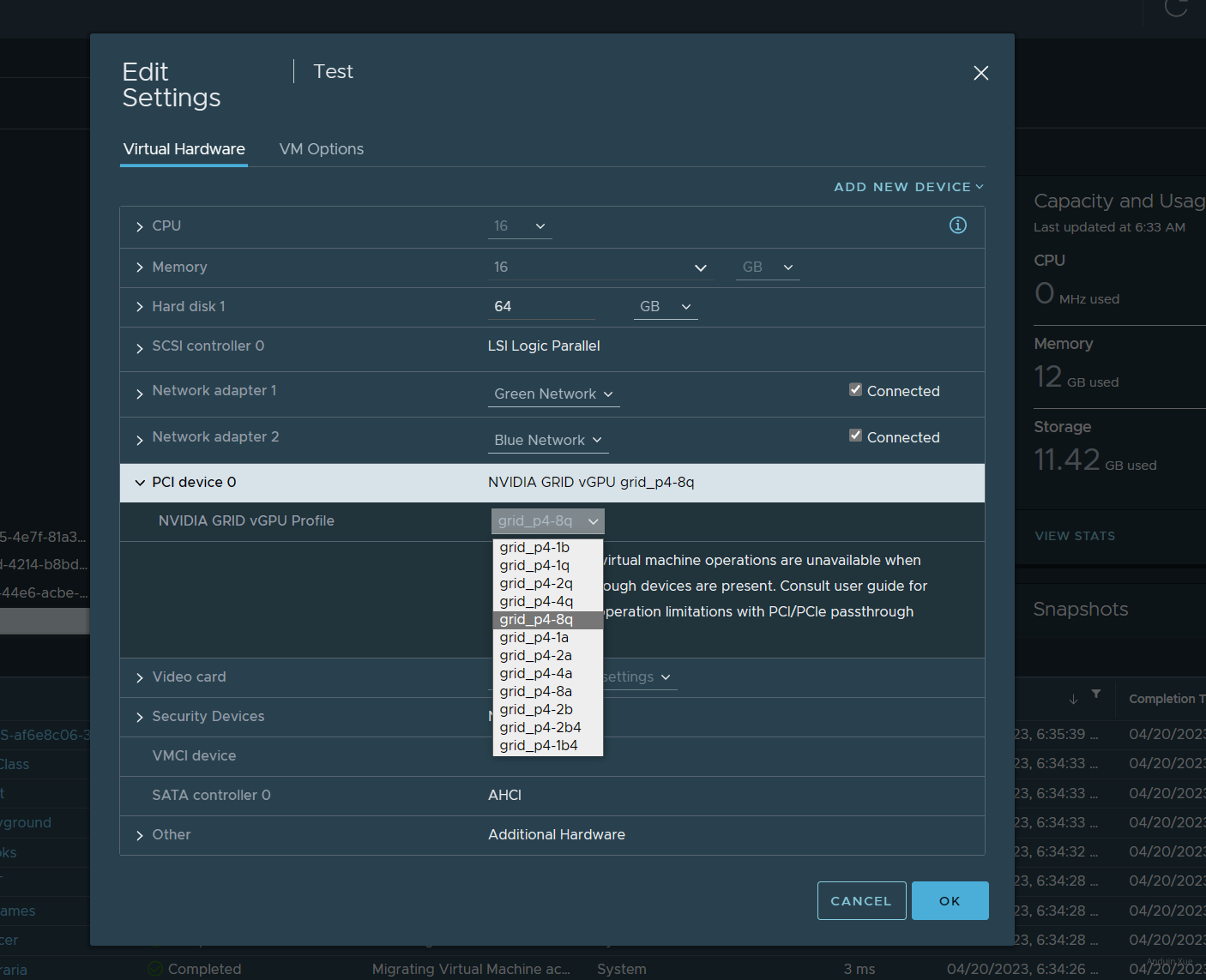
在为虚拟机分配虚拟GPU时,可以选择不同的vgpu类型。
由于我们需要使用OpenCL/CUDA计算功能,必须确保你选择的GPU类型支持CUDA运算。 一般来说,所有Q-Series和C-Series的vGPU都支持CUDA计算(Tesla M6, Tesla M10, Tesla M60仅8Q支持),而A-Series和B-Series不支持CUDA计算。 请确保选择Q/C Series的vGPU, 建议选择Q-Series,其功能最为强大 详情可以参考 Nvidia用户手册
为虚拟机安装驱动
确保识别到计算卡
在开始安装驱动前,请确保虚拟机已经能够识别到计算卡:
lspci -nn | grep -Ei "3d|display|vga"
lshw -C display
在输出中找到你的计算卡。例如:

为你的虚拟机安装GRID驱动
在前面的步骤中,我们已经下载到了驱动。
一般来讲客户机驱动应与hypervisor驱动版本号一致。驱动有三种分发版本:deb, rpm, runfile。如果你的平台支持安装对应的软件包,则不建议通过runfile安装。
这里以Ubuntu 22.04 LTS举例,将对应版本的驱动下载到服务器上后,可以使用下面命令完成安装:
sudo apt install ./nvidia-linux-grid-525_525.105.17_amd64.deb
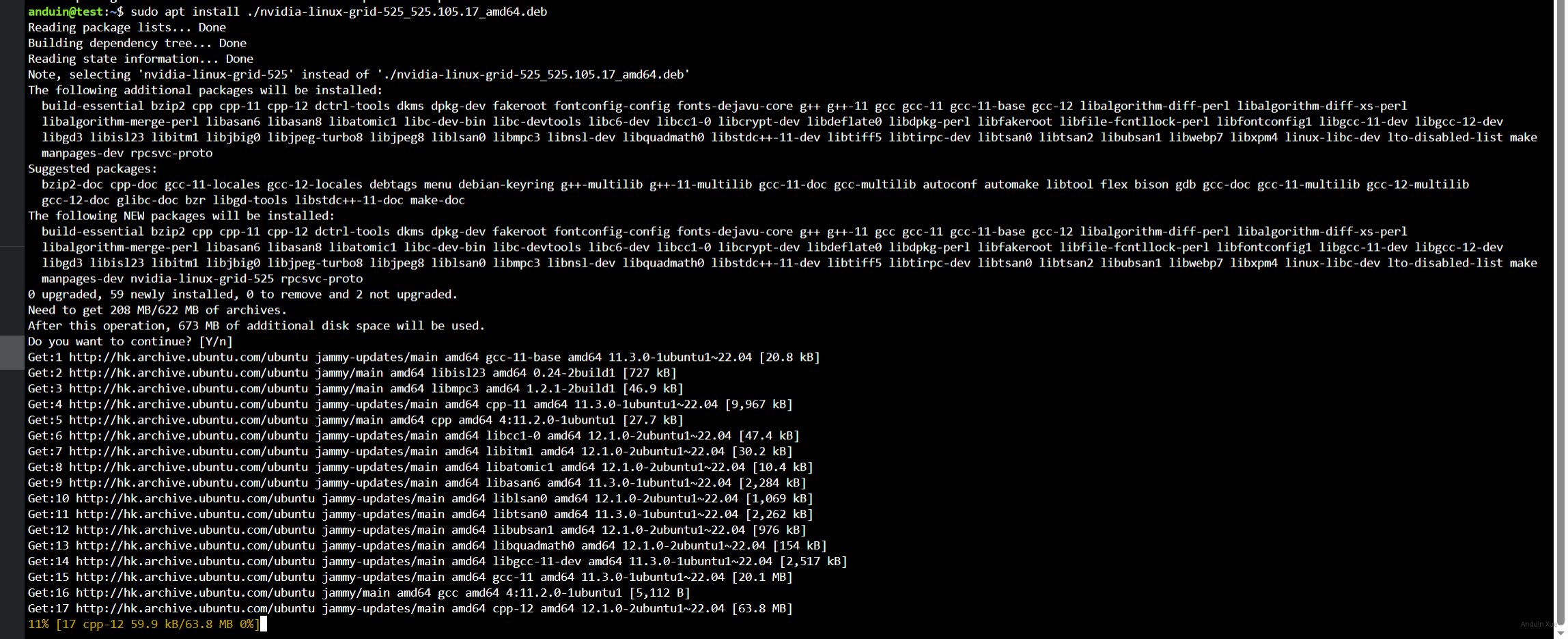
这里我使用了apt install 来完成安装而不是dpkg -i, 因为 apt可以自动安装缺失的依赖。
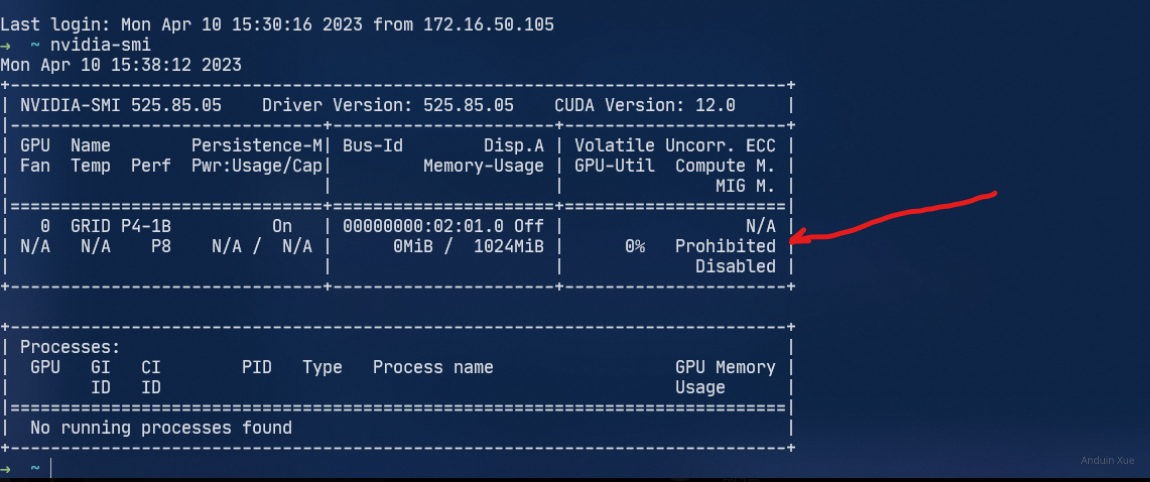
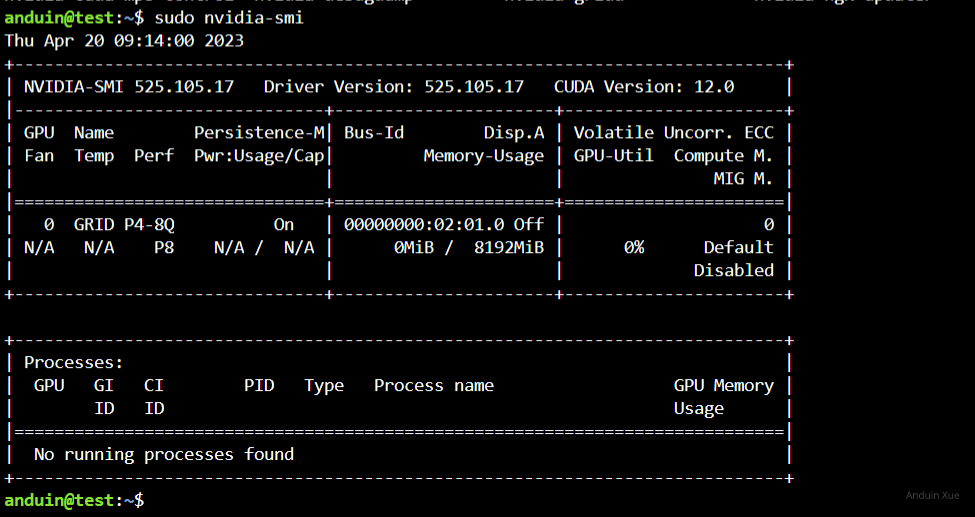
安装完成后,输入nvidia-smi,此时应该可以看到vgpu的信息。
配置 GRID 驱动许可证
首先,编辑gridd配置文件:
sudo vim /etc/nvidia/gridd.conf
找到FeatureType并将其改为改为1, 其它选项保留不动即可。
接下来进入/etc/nvidia/ClientConfigToken(如果没有则创建),将前面下载到的Client Configuration Token放入,然后使用chmod 744为其修改权限。
完成后,重启nvidia-gridd:
sudo systemctl restart nvidia-gridd.service
最后用nvidia-smi -q | grep License确认许可已被正确安装,如果正确安装,你应该可以看到类似下面一段内容:
vGPU Software Licensed Product
Product Name : NVIDIA RTX Virtual Workstation
License Status : Licensed (Expiry: 2023-4-20 12:14:21 GMT)

安装 CUDA
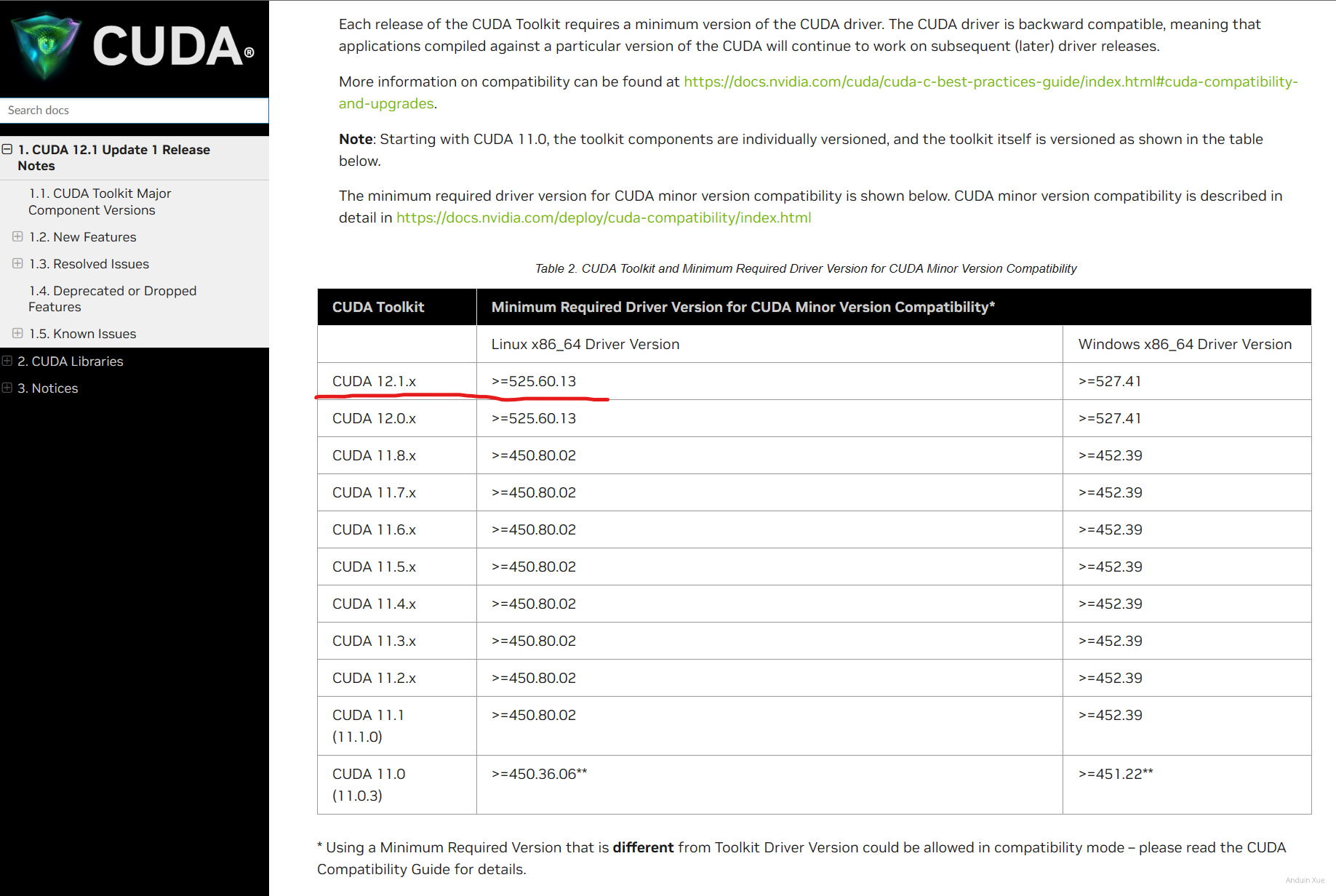
注意:在选择Cuda版本时需要注意,一般来讲Grid驱动会落后标准Nvidia驱动几个版本,因此可能无法安装最新版本的 CUDA, 你可以在cuda-release-note中看到不同的cuda版本对驱动的版本要求。
注意: 只要是Linux系统,无论是什么发行版,不可以使用平台软件包(deb,rpm等)来安装cuda-toolkit,而是必须使用runfile安装!如果使用平台软件包安装,在安装时cuda-driver会与已安装的grid-driver冲突,导致安装无法继续!
注意: 只要是Linux系统,无论是什么发行版,也不要试图使用包管理安装。
sudo apt install nvidia-cuda-toolkit。这个命令会移除 Grid 驱动!
在这里查看 CUDA 对 NVIDIA 驱动的要求: https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
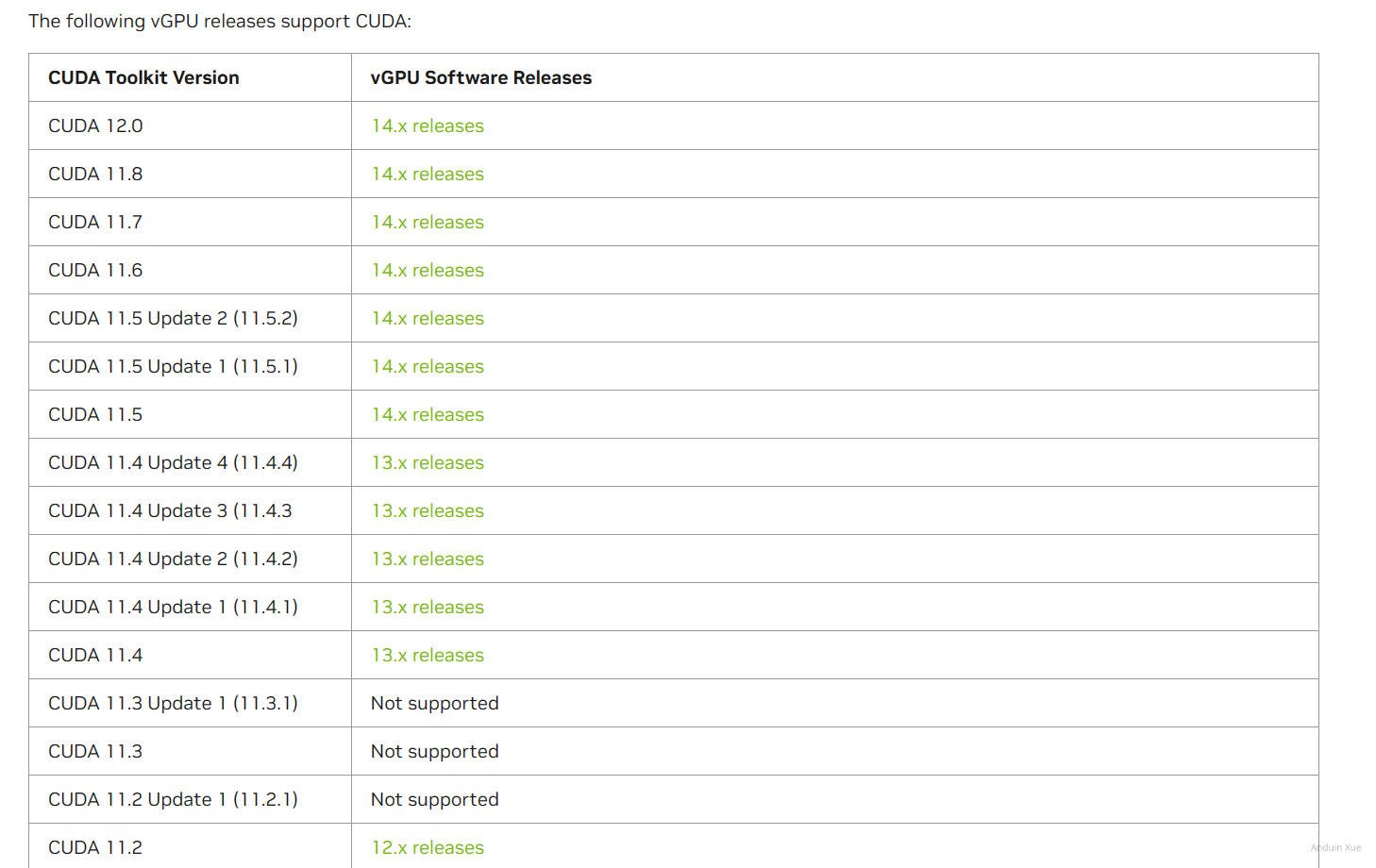
在这里查看 VGPU 对 CUDA 的支持情况: https://docs.nvidia.com/cuda/vGPU/index.html
注意:一些AI软件也有CUDA版本要求,也应该根据它的文档确定应该安装的cuda版本.
打开cuda-toolkit-archive,选择你想安装的版本,然后选择你对应的系统即可获得对应的 CUDA toolkit下载链接。
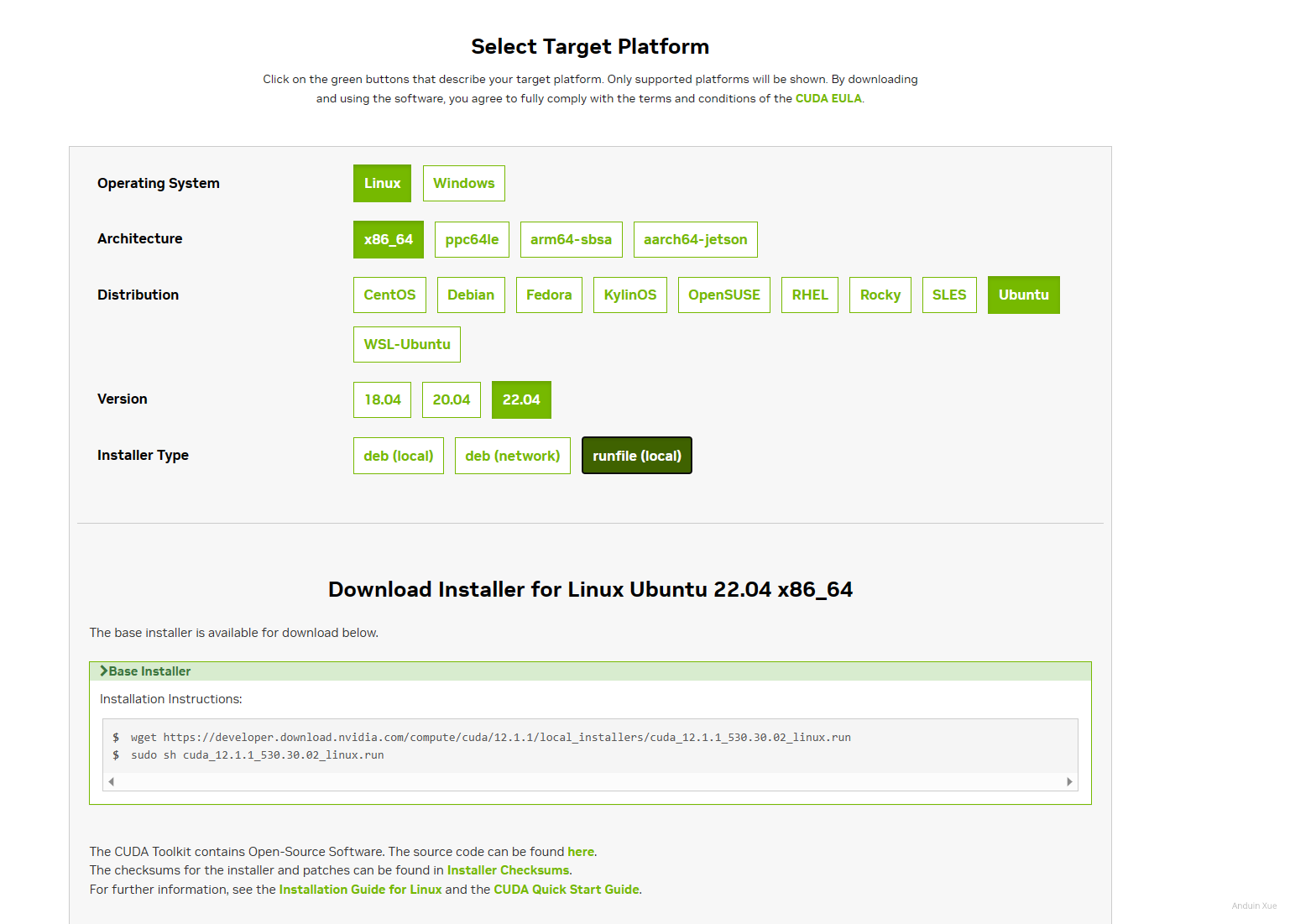
注意: cuda-repo-ubuntu2204-12-1-local_12.1.1-530.30.02-1_amd64.deb 这个文件可能会比较大(大约 3GB)
下载完runfile后,使用sudo运行。

在第一个协议许可页面输入 accept:
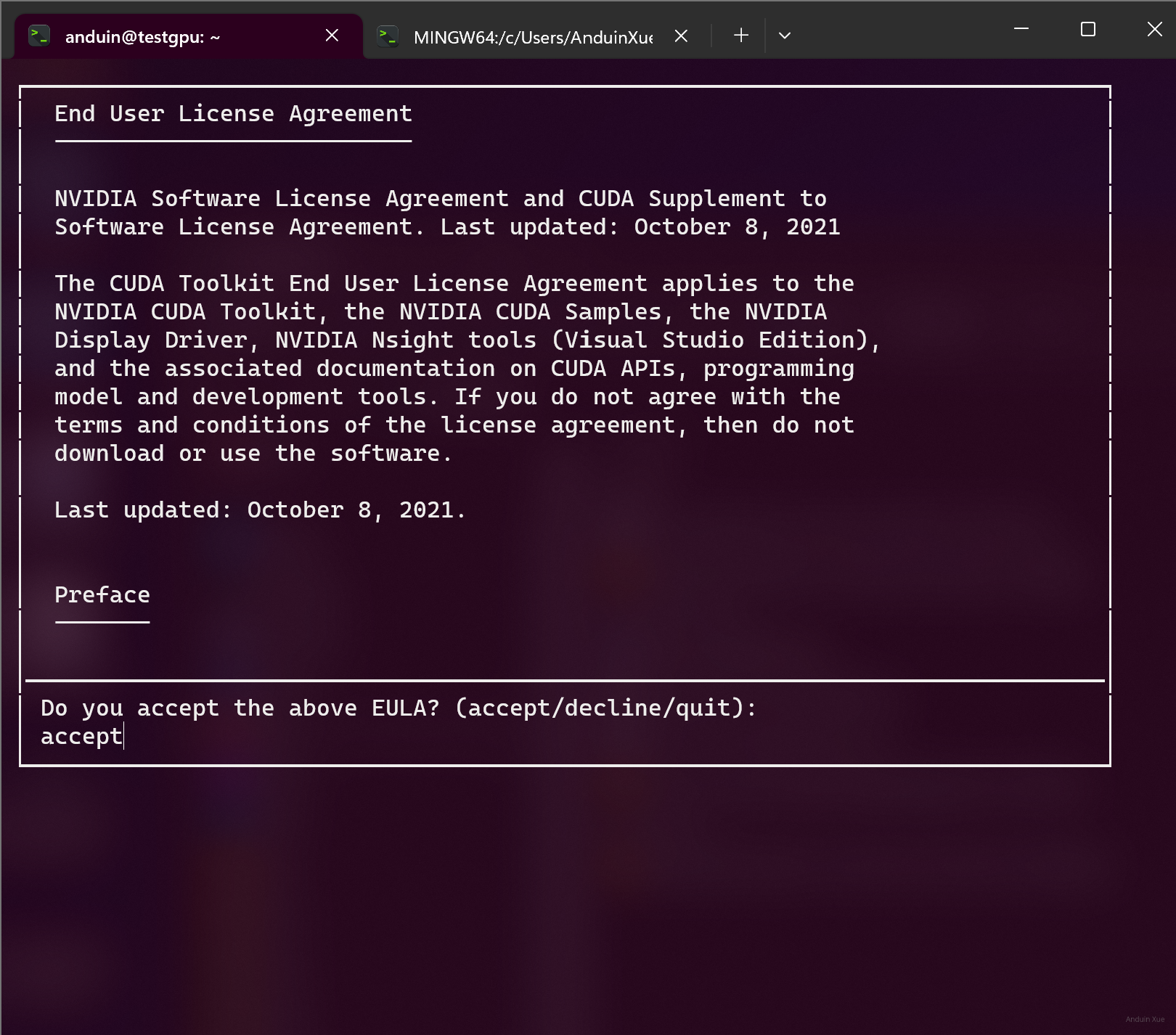
然后在选择组件界面,取消勾选安装cuda-driver,否则grid驱动会被覆盖!
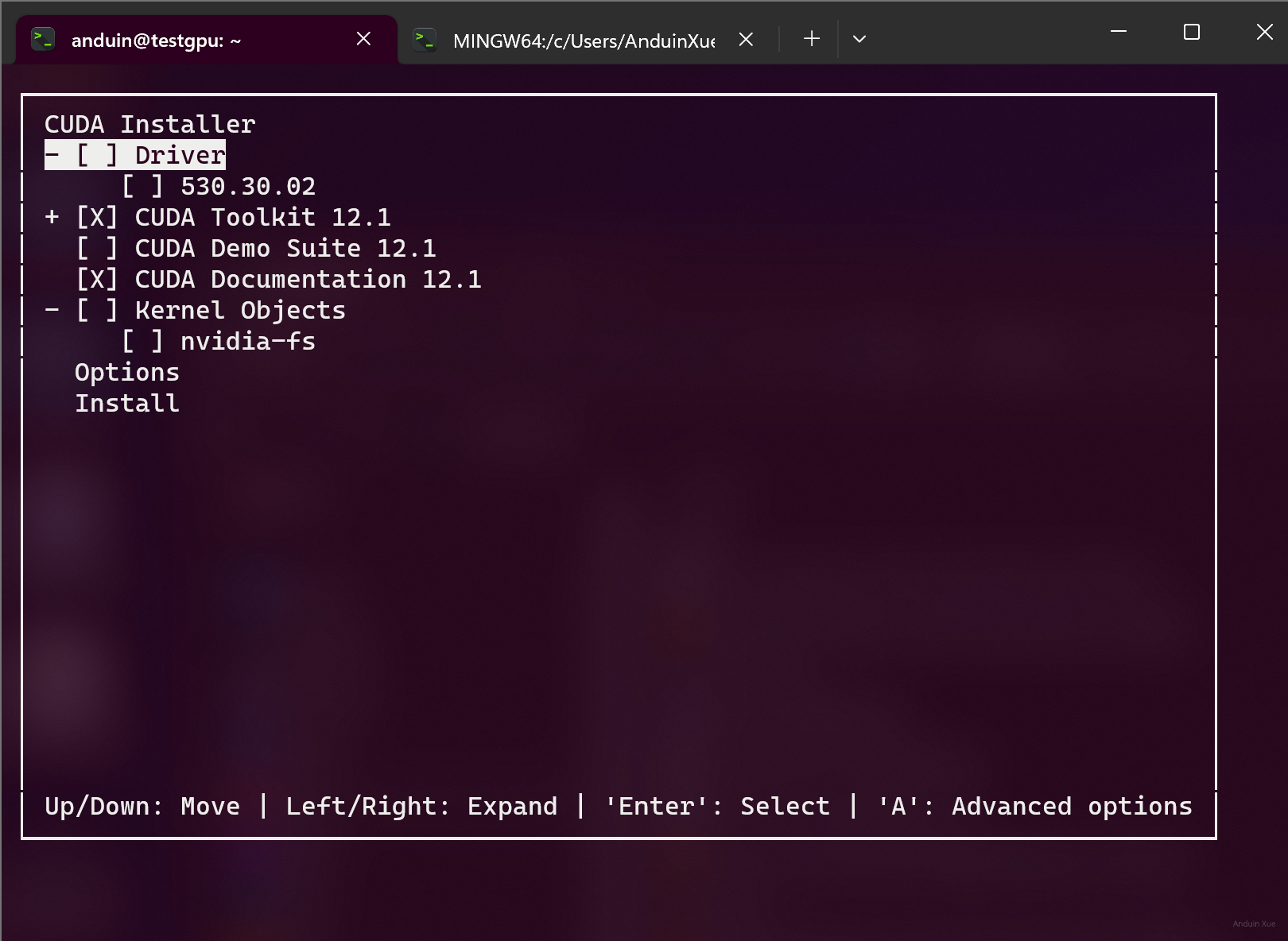
安装完成后,编辑系统PATH环境变量 sudo vim /etc/environment
在PATH末尾加入:/usr/local/cuda/bin (版本号自行按需修改)
重新启动你的shell,然后使用下面命令确认CUDA已完成安装:
nvcc --version
最后,考虑到需要大批量部署,我还是写了一个方便自己用的脚本:
# 我把驱动、CUDA和License都挂载到了 /mnt/Shared/nv/
sudo lspci | grep NVIDIA
cd /mnt/Shared/nv/
sudo apt install ./nvidia-linux-grid-525_525.105.17_amd64.deb -y
sudo nvidia-smi
sudo rm /etc/nvidia/ClientConfigToken/client_configuration_token*
sudo cp ./client_configuration_token_22-04-2023-15_14_46.tok /etc/nvidia/ClientConfigToken
sudo chmod 744 /etc/nvidia/ClientConfigToken/client_configuration_token_22-04-2023-15_14_46.tok
sudo systemctl restart nvidia-gridd.service
sleep 10
sudo nvidia-smi -q | grep License
sudo ./cuda_12.1.1_530.30.02_linux.run
PATH="$PATH:/usr/local/cuda-12.1/bin"
echo "PATH=\"$PATH\"" | sudo tee /etc/environment > /dev/null
source /etc/environment
nvcc --version
nvidia-smi
确保虚拟机可以跨主机迁移
在完全配置好 GRID 和 CUDA 后,虚拟机仍然是可以在主机之间平滑迁移的。
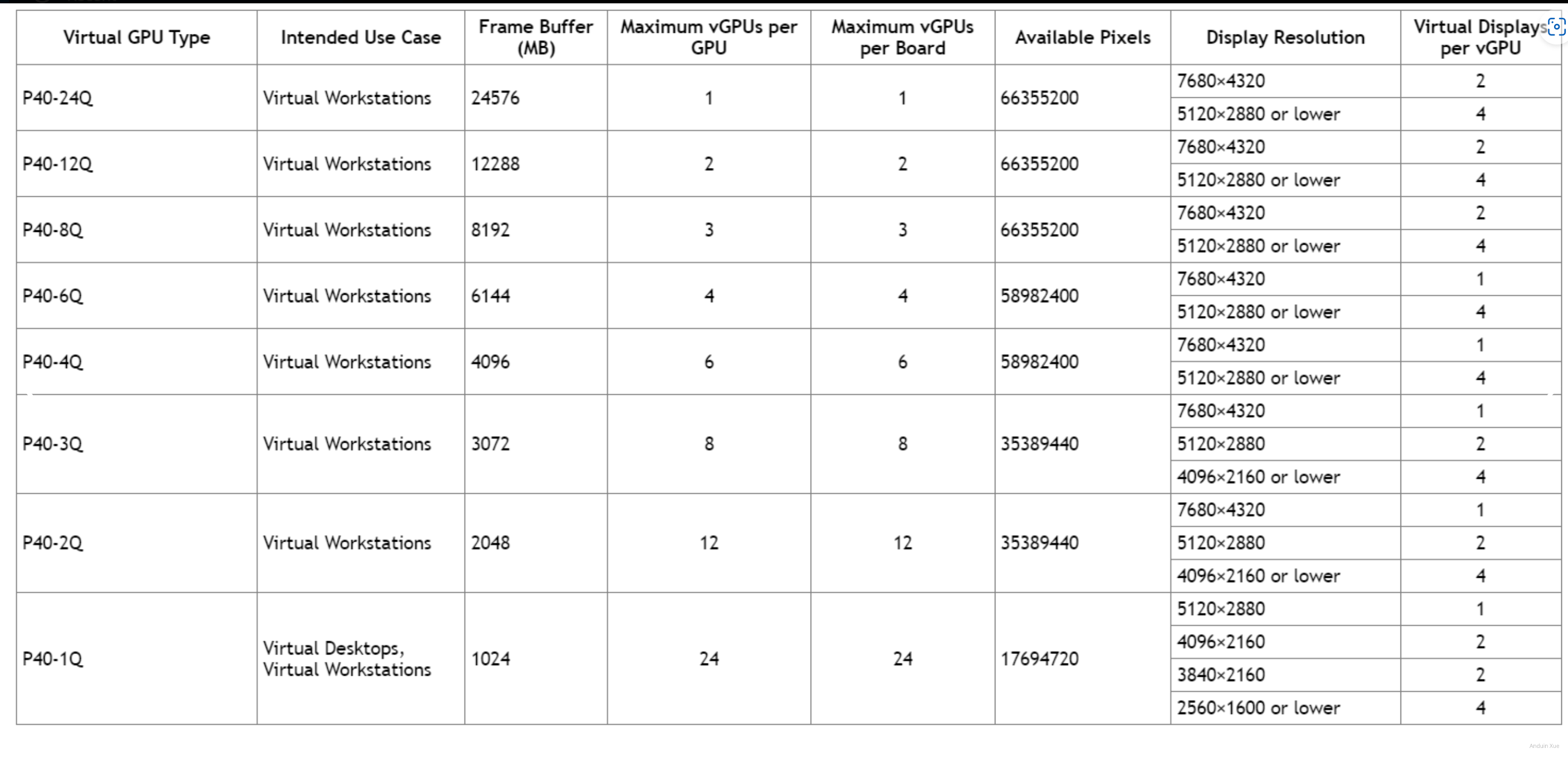
划分 SKU
注意:你的GPU一旦分配了一台 3q (3G 显存的VM),它就不能分配其它类型的 vGPU了。
例如:对于P40,一共24GB显存,你可以分配 3 个 8GB 显存的 VM,但是一旦按照 8GB 显存切分,它就不能继续分配 4GB 显存或 2GB 显存的机器!
因此,你必须提前规划,每一个物理 GPU 如何切分。这里我建议设计两个分法:
- 1/8 GPU,每个 vGPU 有 3GB 显存。(用于简单的游戏、编解码、计算)
- 1/3 GPU,每个 vGPU 有 8GB 显存。(用于跑大一点的模型)
测试迁移
首先在 VCenter Server 中开启迁移:
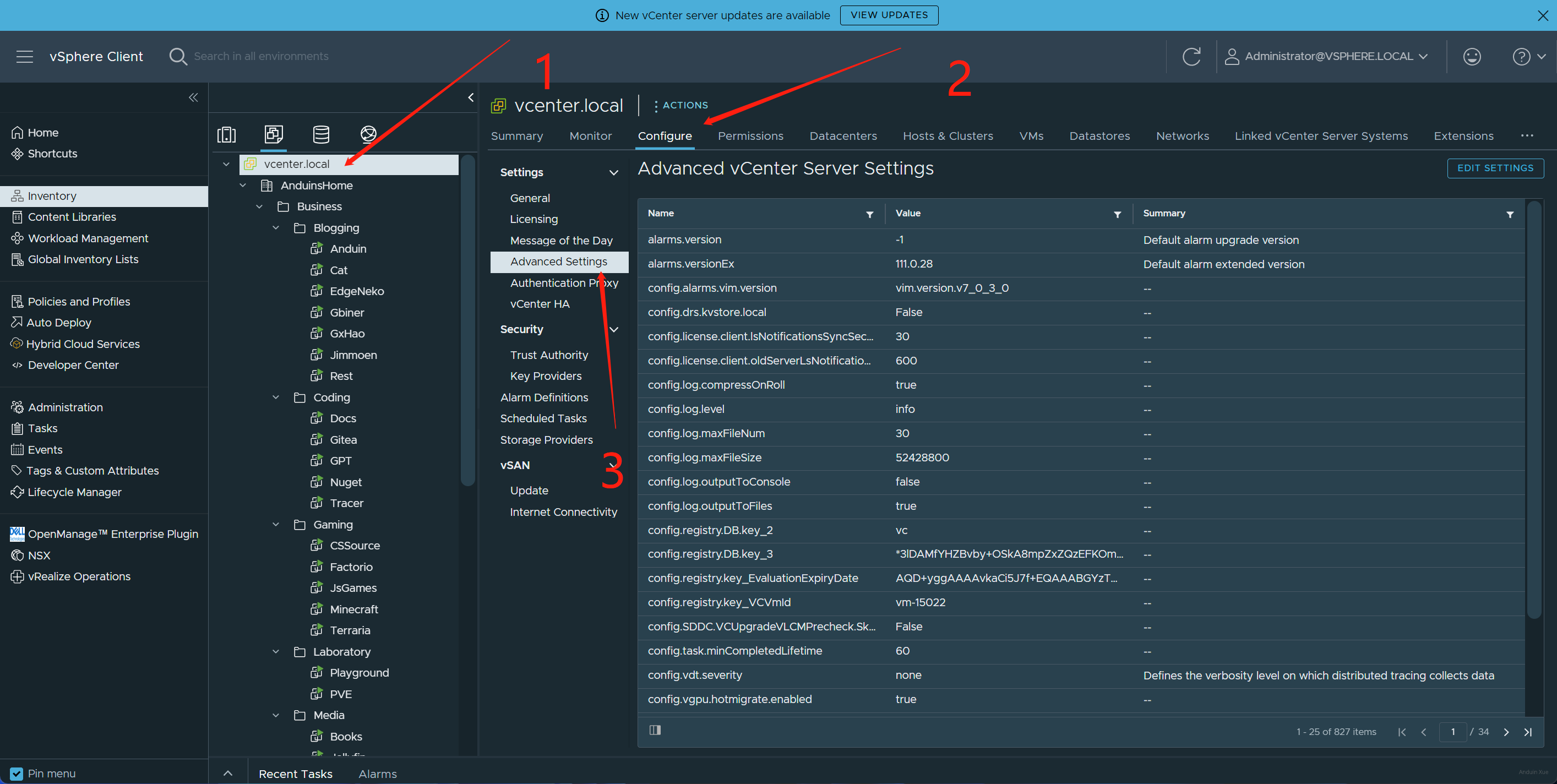
将配置:vgpu.hotmigrate.enabled 这个选项开启。
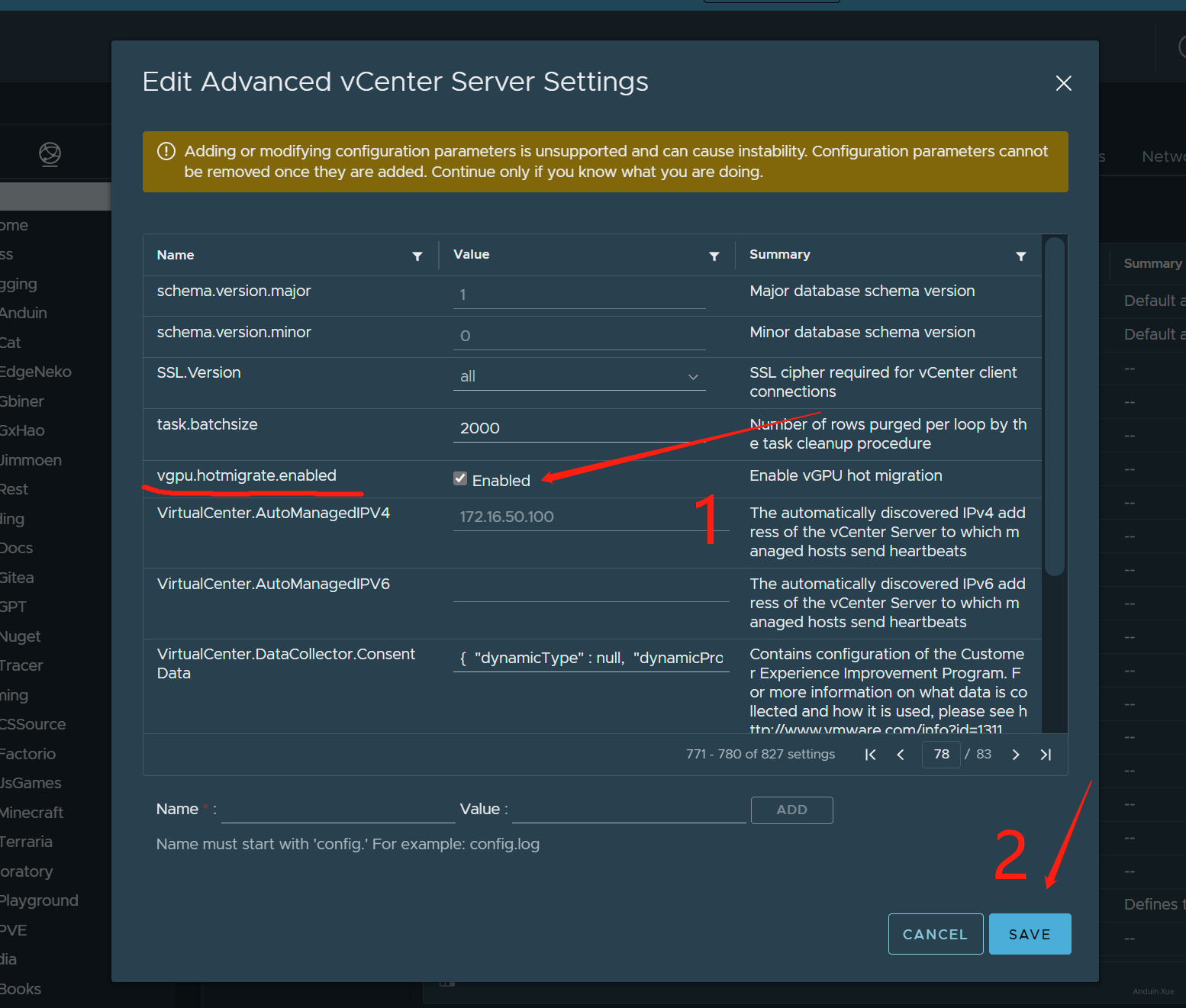
另外,注意统一主机的设置!如果你开启了 ECC,则所有主机都必须开启 ECC!
然后试试迁移吧!注意:vGPU 迁移时,不能跨越不同拆分类型的主机!
例如:如果你的 GPU 是按照 1/8 拆分,每个 vGPU 3GB 显存,那么你不可能把 3GB 显存的 vGPU 迁移到 1/3 拆分的显卡上。
开始炼丹
你已经全搞定了。开始炼丹吧!
安装 cuDNN
对于许多 App,都需要 cuDNN 来炼丹。
先安装一下 cuDNN 吧!这里详细介绍了在 Ubuntu 22.04 上安装 cuDNN 的过程:https://anduin.aiursoft.cn/post/2023/4/24/how-to-install-cuda-and-cudnn-on-ubuntu-2204-and-test-if-its-installed-successfully.
视频编码
在驱动安装完以后,你已经可以使用 GPU 进行硬件加速的编码了。
直接使用 ffmpeg 编码,编码器选择:h264_nevnc,试试它能不能成功编码。
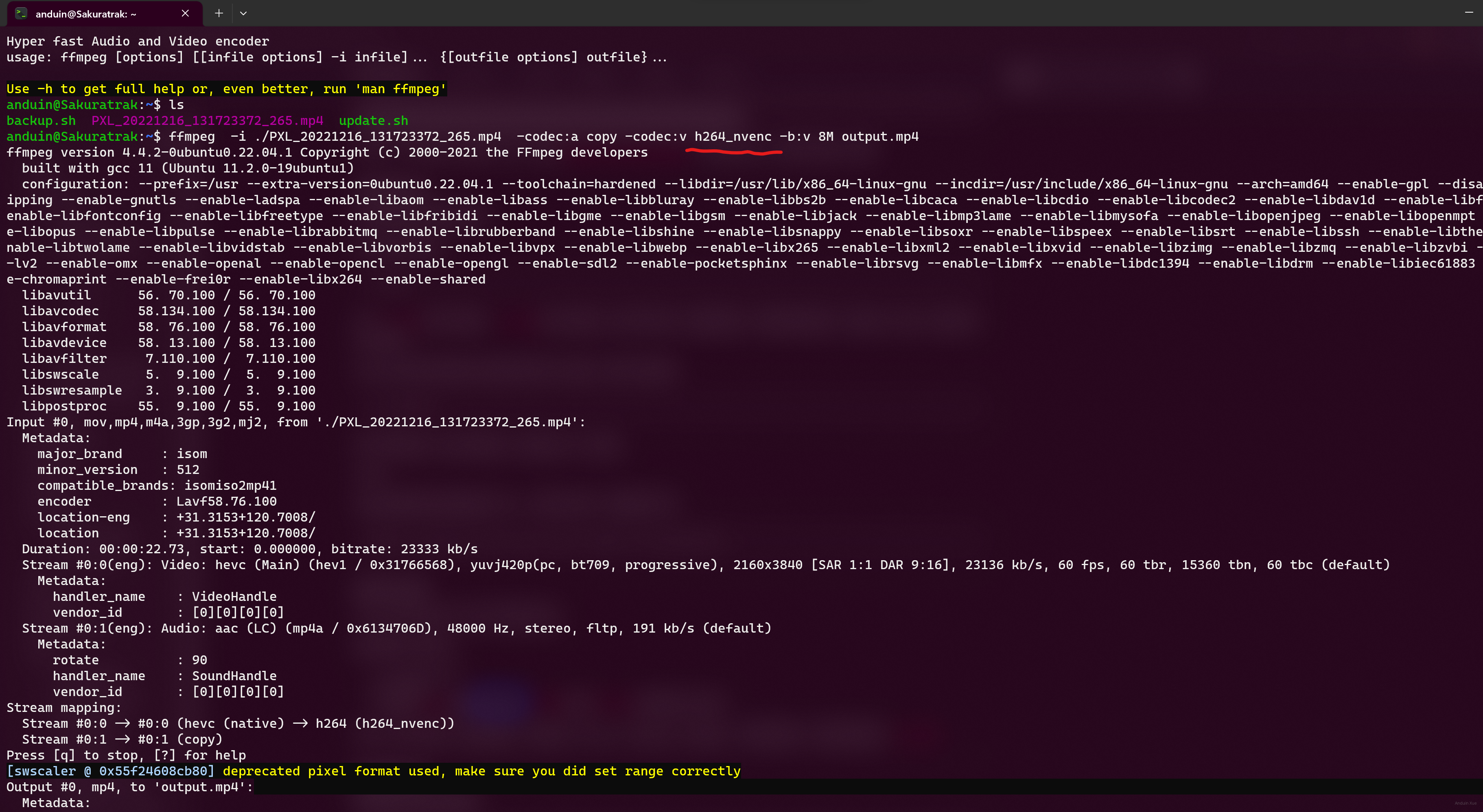
编码的时候,可以检查 GPU 的算力占用情况。
一般编解码视频只需要几百 MB 显存。
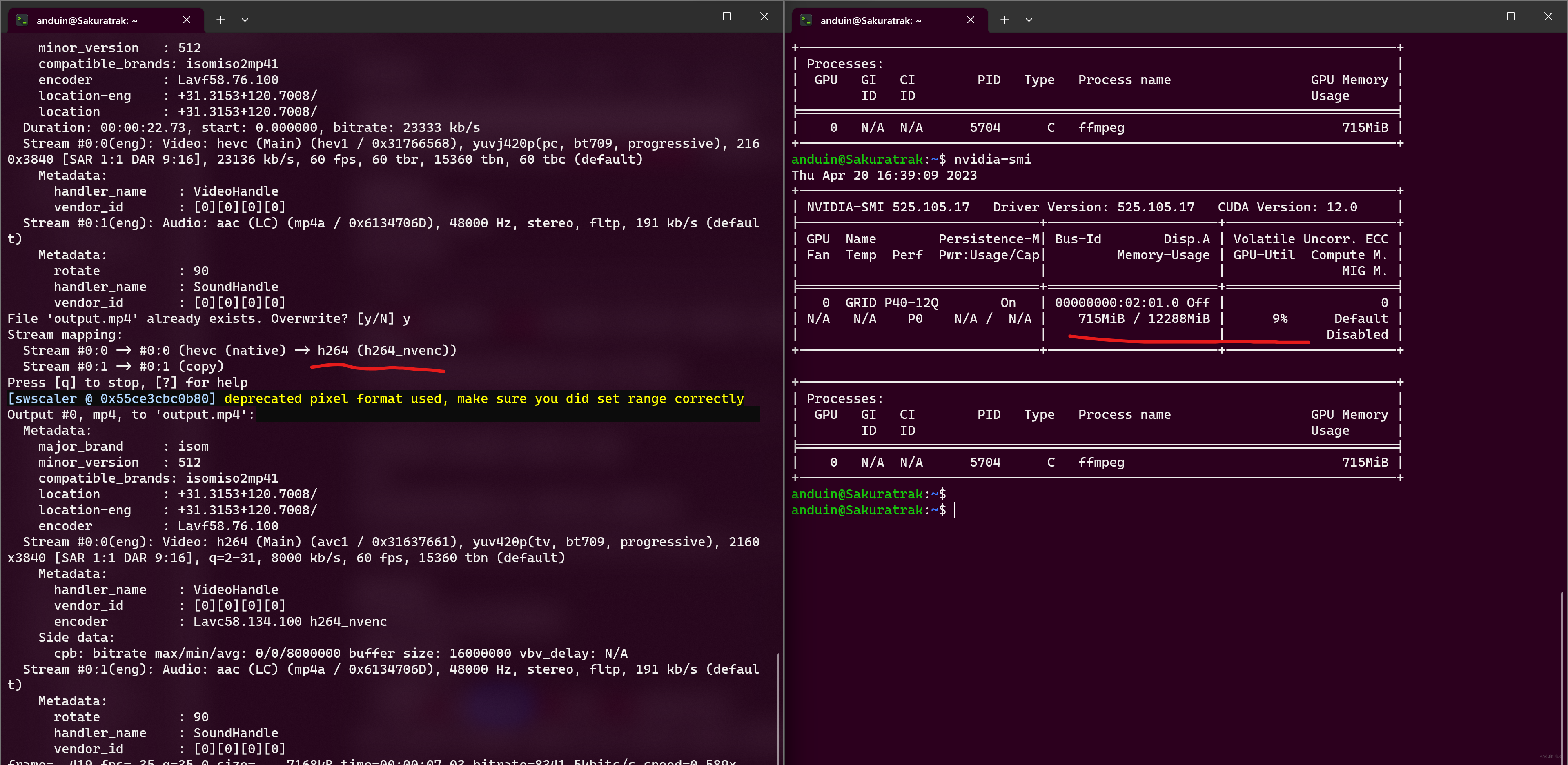
如果ffmpeg能够正常编解码了,那么你使用的媒体应用大概率也可以开启硬件加速了。
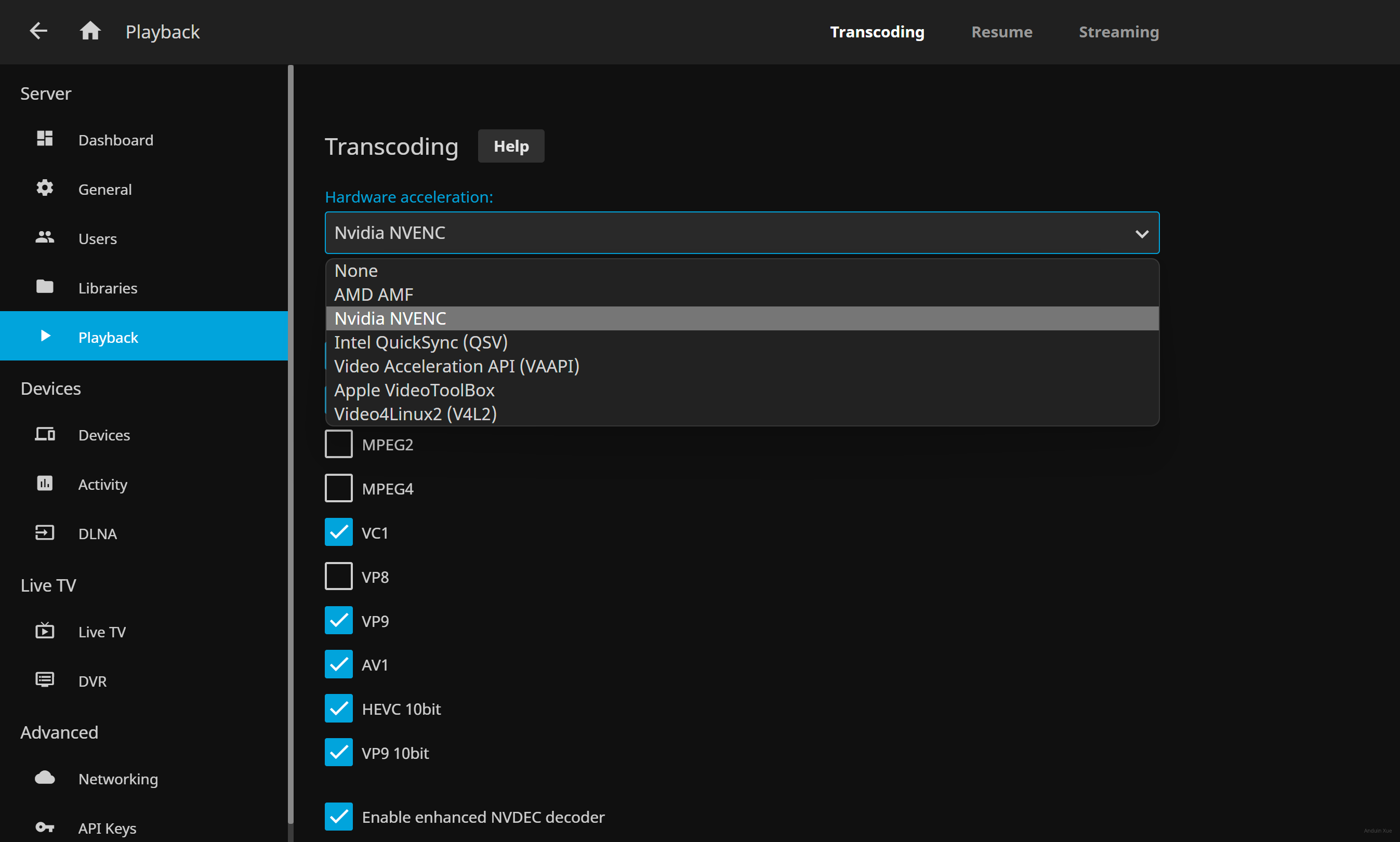
在硬件加速编解码时,你同样可以看到显卡在被占用:
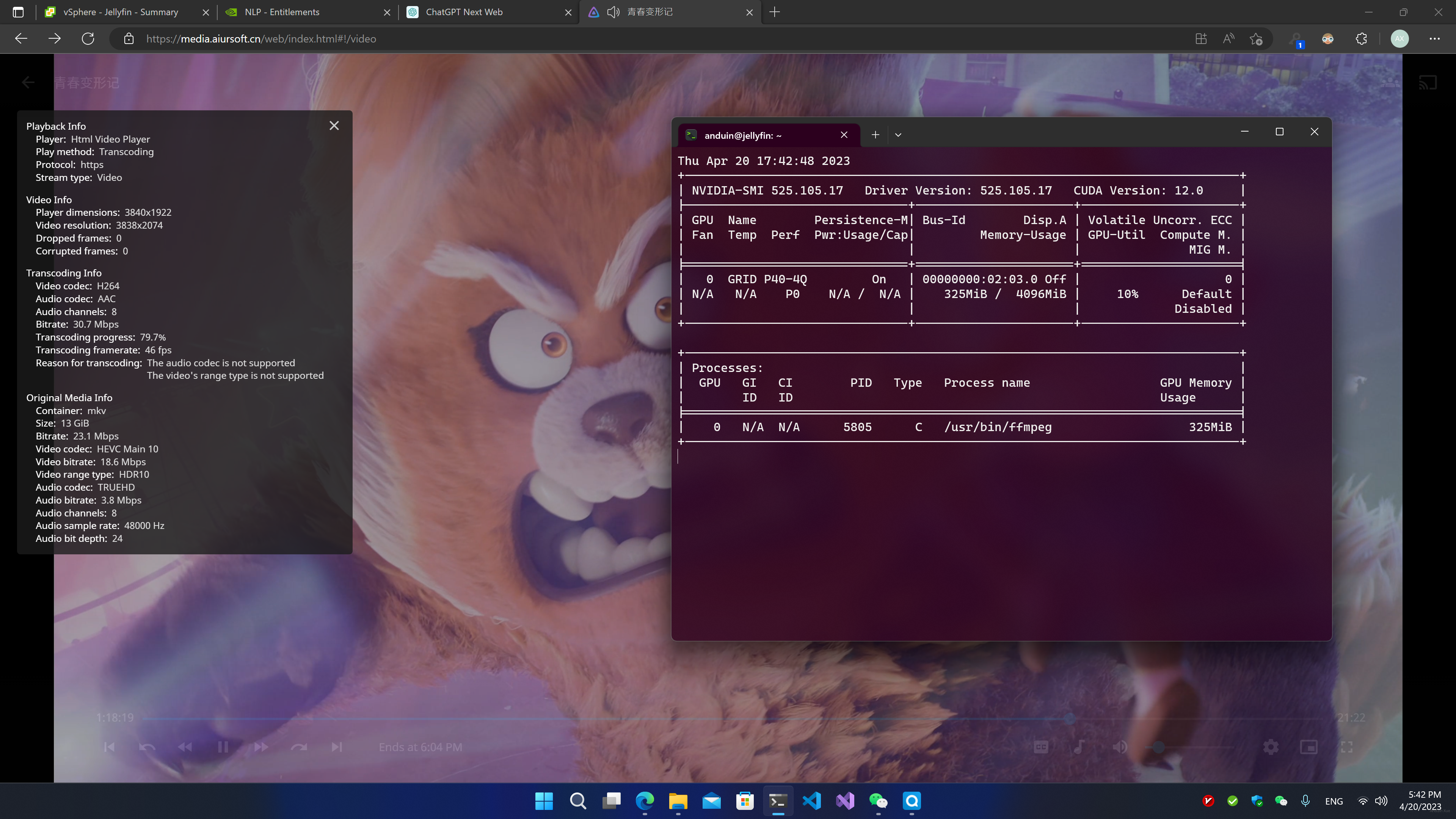
运行 AI 应用
这里安利几个可以在本地 P40 上运行的 AI 项目!
- https://git.aiursoft.cn/PublicVault/ChatGLM-6B
- https://git.aiursoft.cn/PublicVault/gpt4all
- https://git.aiursoft.cn/PublicVault/minGPT
- https://git.aiursoft.cn/PublicVault/stable-diffusion-webui
有一些常见的库,或许你的 AI 应用需要:
sudo apt install python3
sudo apt install libgl-dev
直接运行 Clone 下来的 Stable Diffusion WebUI 即可运行:
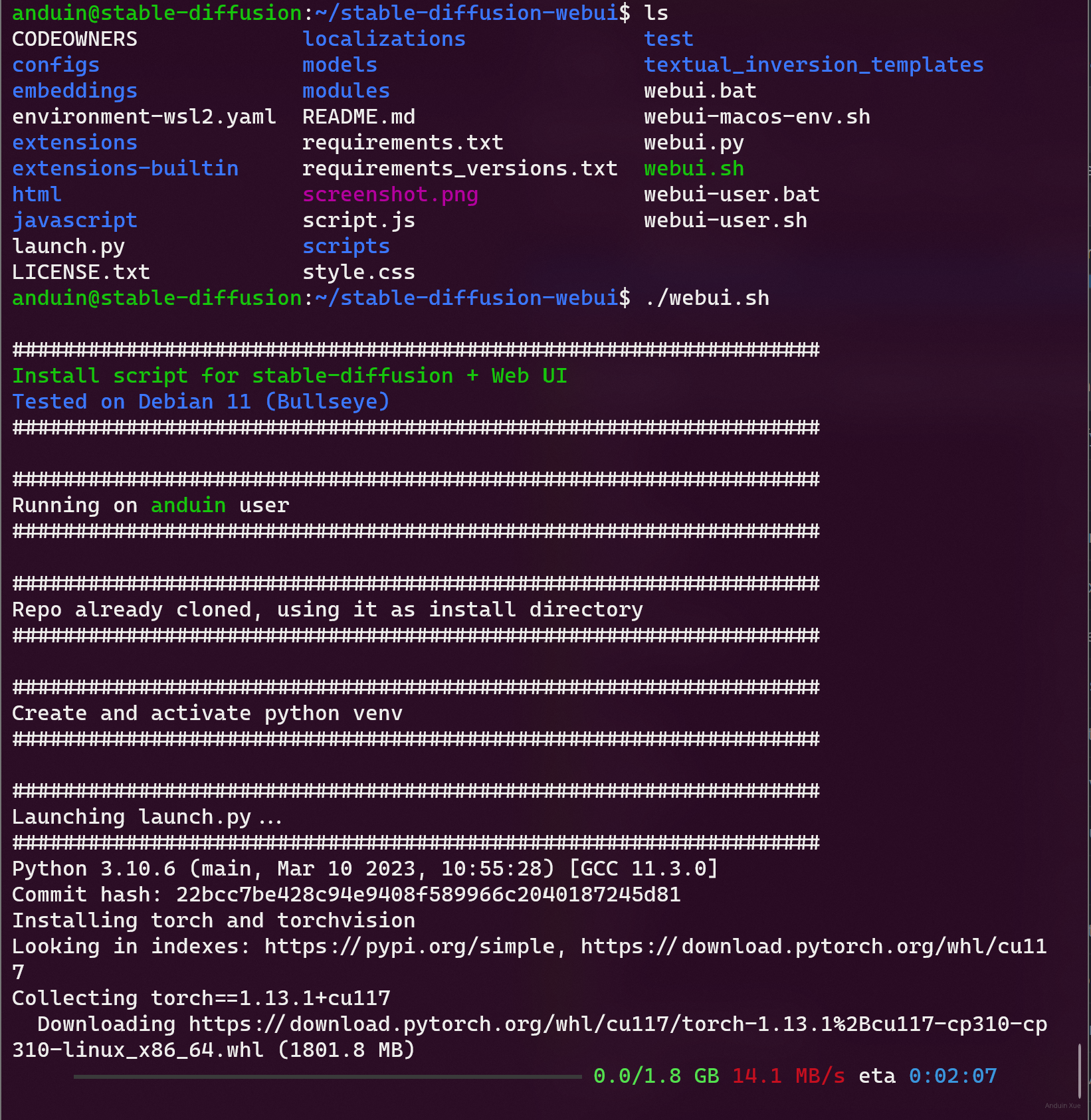
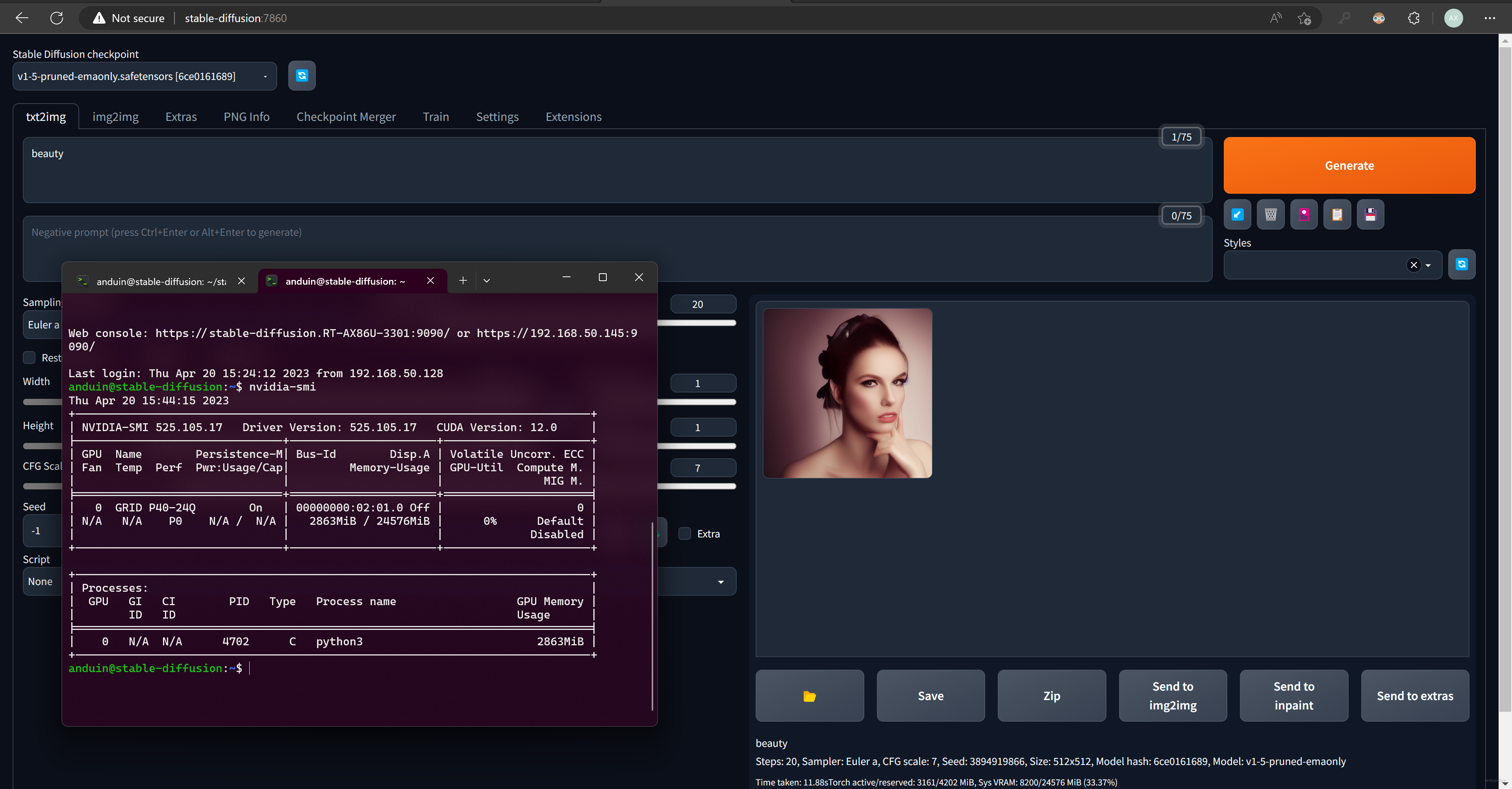
在使用 Stable Diffusion 的时候,你可以在 nvidia-smi 里看到 Python 正在使用显卡,以及显存的用量。
监控温度 - 如果你不想吵
服务器的风扇一般都会有非常大的噪音以降低 CPU 和 PCIE 设备的噪音。但是,如果你的服务器放在家里,这就会成为一大烦恼。
你需要有效的方法,得到服务器的温度,然后求出风扇转速来写一个程序控制风扇转速。
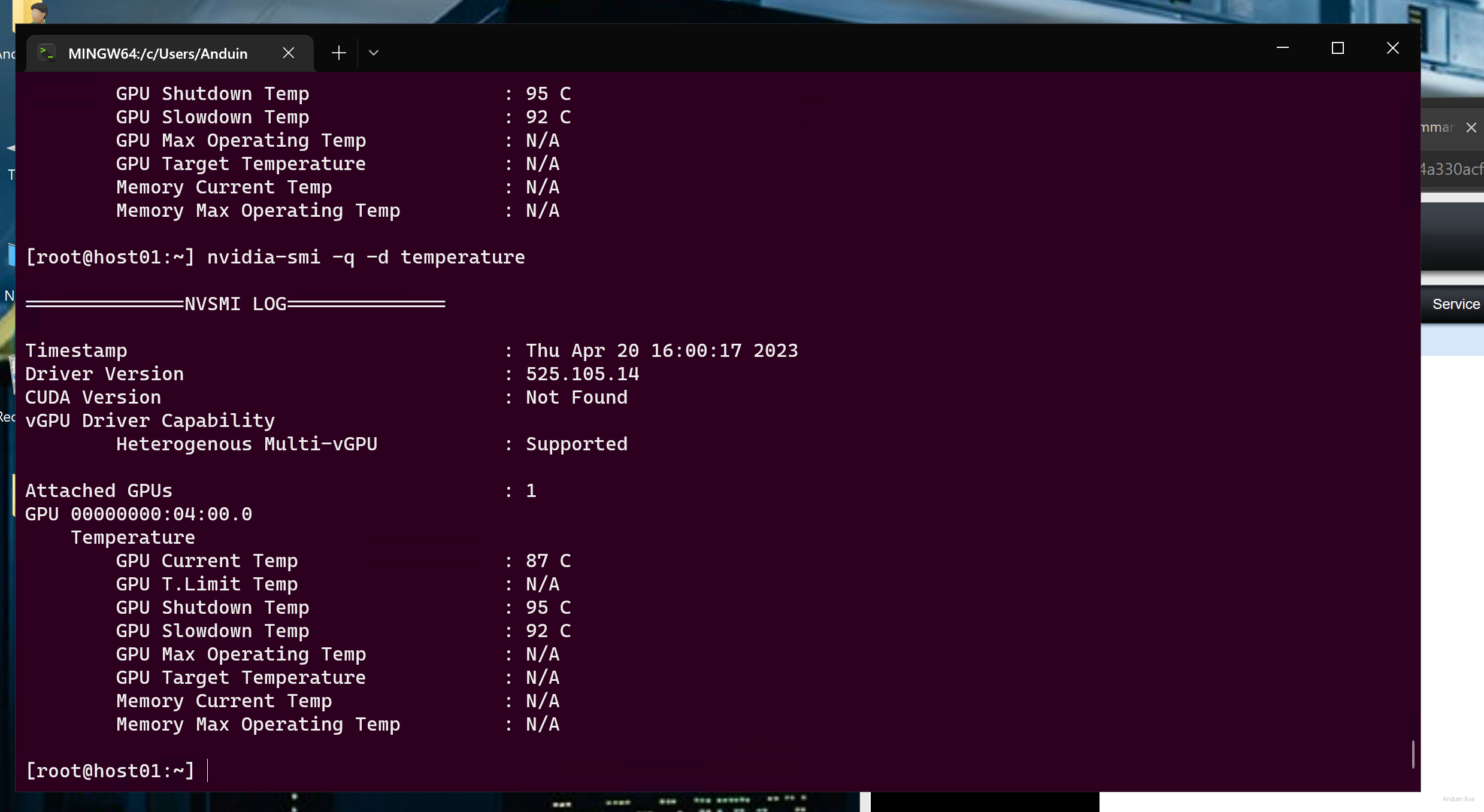
获取风扇转速的方法是,在主机上(注意:不是 vGPU)运行:
nvidia-smi -q -d temperature
如果发生了问题……
有 GPU 算力数据中心比纯 CPU 算力的数据中心要难管理的多。
一般出了问题,首先检查:
- vGPU 授权成功了没有
nvidia-smi -q
然后如果最近有变更,需要检查下面几项:
- Linux 内核要支持 Grid Driver
- Host Driver 要和 Guest Driver一致
- Guest Driver 和 CUDA 要一致(或支持此版本的 CUDA)
- CUDA 要和要跑的 AI 应用要至此。
另外检查:
- 主机的 BIOS 设置中,是否开启了
- IO MMU
- PCIE AER
- SR IOV(虽然我们的显卡不用 SR IOV,但是我还是建议开启这个选项)

别忘了检查:
- VCenter 里 是否能够识别到卡,是否设置为 Shared Direct Vendor shared passthrough graphics
- 物理 GPU 的设置是否一致(例如:开关 ECC)
文章中关于vGPU迁移的注意事项非常关键,尤其是在跨主机迁移时对显存分配策略的依赖。实际生产环境中,如果物理GPU被拆分成不同显存规格的vGPU(如1/8和1/3),是否需要为每个集群节点预设相同的显存分配方案?这可能对资源调度系统提出更高要求——当某个节点剩余显存不足以满足迁移目标时,如何动态调整vGPU配置?目前vSphere的调度策略是否支持这种细粒度的资源匹配?
CUDA驱动版本与主机驱动的强绑定关系带来维护挑战。当需要升级CUDA时,是否必须同步更新所有主机的NVIDIA驱动?这种版本耦合度是否会影响集群的弹性扩展能力?对于混合使用多代GPU的集群,是否存在驱动兼容性冲突的风险?
关于温度监控部分,文章提到通过nvidia-smi获取温度数据。但在虚拟化环境中,物理GPU的温度监控是否需要额外配置?当多个vGPU同时高负载运行时,如何避免因温度过热触发的自动降频影响计算性能?是否有更高效的散热策略建议,特别是针对家庭环境部署的静音需求?
在AI模型训练场景中,文章推荐了ChatGLM-6B等项目。但P40的24GB显存在运行更大模型(如LLaMA 70B)时,是否可以通过模型并行拆分到多个vGPU?这种拆分对vSphere的GPU虚拟化技术有何特殊要求?实际测试中vGPU的显存分配是否支持非对称拆分,以适应不同模型的显存需求差异?
最后,关于vGPU授权的稳定性问题,当物理GPU被划分为多个vGPU时,如果其中一个vGPU因授权问题失效,是否会影响整个物理GPU的可用性?目前NVIDIA的授权机制是否支持按需动态分配,以避免因部分vGPU故障导致整体资源浪费?
根据上述文章内容,我们可以逐步解析如何设置一个高效的GPU虚拟化环境用于AI应用:
准备硬件和软件环境:
配置vSphere虚拟化平台:
优化虚拟机性能:
安装和配置AI应用环境:
监控和维护:
通过以上步骤,用户可以在虚拟化环境中高效利用GPU资源,支持各种AI应用的运行。遇到问题时,首要检查授权状态和配置设置,确保每一步都准确无误。
这篇博客详细介绍了如何在数据中心中部署和使用 GPU 算力。作者从安装和配置 NVIDIA vGPU 驱动、安装 CUDA、确保虚拟机可以跨主机迁移、测试迁移、运行 AI 应用等方面进行了详细的描述,附带了许多截图和代码片段,便于读者理解和操作。
博客的优点在于内容详实、举例充分,能够帮助读者快速了解和掌握如何在数据中心中部署和使用 GPU 算力。此外,作者还提供了一些常见问题的排查方法,以及如何监控温度等实用技巧。
在改进方面,博客的结构可以进一步优化。例如,将一些注意事项和警告提前到相应步骤之前,以便读者在操作时能够提前了解注意事项。另外,可以考虑将一些步骤拆分成更小的子步骤,以便读者更容易跟踪和理解。
总的来说,这是一篇内容丰富且实用的博客,对于希望在数据中心中部署和使用 GPU 算力的读者来说,具有很高的参考价值。希望作者继续分享类似的技术文章,帮助更多的读者解决实际问题。
太厉害了
太牛了
安度因 日你牙