用 OpenVINO 去和 DeepSeek 对话
最近 DeepSeek 很火。而我买的新笔记本是 Lunarlake CPU: Intel® Core™ Ultra 7 Processor 258V。按说这颗 CPU 里自带了一颗 NPU,如果我单纯傻傻的用 CPU 来搭建 DeepSeek 的话,性能会很差。
最开始的尝试 - 用 CPU 去跑 DeepSeek
用 CPU 去跑 DeepSeek 不难。首先安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
然后拉下来 DeepSeek 的模型:
ollama pull deepseek-r1:32b
32B 的模型大概吃了 22GB 的内存。我 32GB 内存刚好够用。
接下来就可以正常对话了。可以使用 Open WebUI 去搭一个简单的 Web 服务:
pipx install open-webui
open-webui serve
直接打开浏览器的:http://localhost:8080 就可以看到一个简单的 Web 对话框了。
显然,Lunarlake 的 CPU 最不擅长的就是多核计算。DeepSeek 的模型是一个很大的模型,在我的笔记本上这么跑也就图一乐。根本没有实际价值。
OpenVINO
OpenVINO(开放视觉推理和神经网络优化) 是英特尔开发的一个开源工具包,旨在加速人工智能(AI)和机器学习模型的训练与推理。它的目标是帮助开发者高效地在英特尔硬件(如 CPU、GPU 和 VPU)上部署 AI 应用程序。
- OpenVINO 支持将多种深度学习框架(如 TensorFlow、PyTorch、ONNX 等)训练的模型转换为中间表示(Intermediate Representation, IR),并进行优化以提高性能。
- OpenVINO 可以在云端和边缘设备上运行,适用于各种场景,包括计算机视觉、自然语言处理等。
- OpenVINO 通过硬件加速(如英特尔 CPU、NPU和显卡)显著提高模型推理速度。
安装 NPU 的驱动
最开始我因为不知道需要安装 NPU 的驱动,所以直接安装了 OpenVINO。结果发现 OpenVINO 无法找到 NPU。后来我才知道,需要安装 NPU 的驱动。
我使用的是 AnduinOS 1.2.0,相当于 Ubuntu 24.10。首先来到 https://github.com/intel/linux-npu-driver/releases 下载最新的驱动。
wget https://github.com/intel/linux-npu-driver/releases/download/v1.13.0/intel-driver-compiler-npu_1.13.0.20250131-13074932693_ubuntu24.04_amd64.deb
wget https://github.com/intel/linux-npu-driver/releases/download/v1.13.0/intel-fw-npu_1.13.0.20250131-13074932693_ubuntu24.04_amd64.deb
wget https://github.com/intel/linux-npu-driver/releases/download/v1.13.0/intel-level-zero-npu_1.13.0.20250131-13074932693_ubuntu24.04_amd64.deb
上面的三个包分别是驱动、固件和 Level Zero。上面的链接可能不再是最新的,不要复制粘贴,应该去它的网站上找最新的链接。
同时,我们还需要安装 TBB:
sudo apt update
sudo apt install libtbb12
别忘了安装这三个包:
sudo dpkg -i *.deb
到这一步,我发现 level-zero 并没有安装。我需要手动安装:
wget https://github.com/oneapi-src/level-zero/releases/download/v1.18.5/level-zero_1.18.5+u24.04_amd64.deb
sudo dpkg -i level-zero*.deb
最后,我们需要重启电脑:
sudo reboot
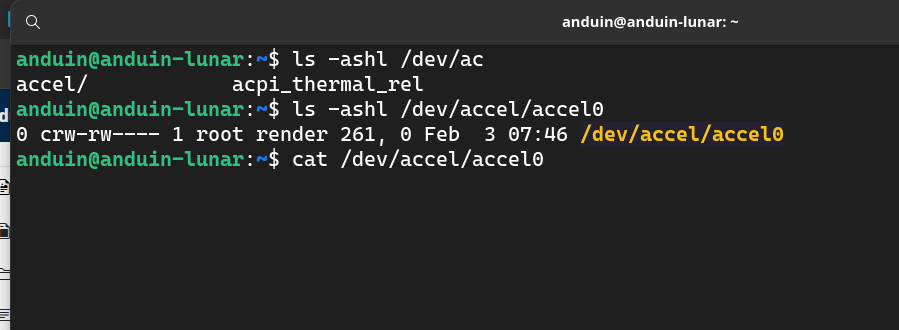
重启完成后,我们将会看到 NPU 的驱动已经安装好了。它会提供一个文件:/dev/accel/accel0。
但是,默认情况下,只有 root 用户才能访问这个文件。我们需要将当前用户加入到 render 组:
# set the render group for accel device
sudo chown root:render /dev/accel/accel0
sudo chmod g+rw /dev/accel/accel0
# add user to the render group
sudo usermod -a -G render $USER
# user needs to restart the session to use the new group (log out and log in)
别忘了注销再登录。
可以 cat 一下 /dev/accel/accel0,看看是否有输出。如果有输出,说明 NPU 驱动安装成功。
cat /dev/accel/accel0
安装 OpenVINO
OpenVINO 的前端是 Python 写的,后端是 C++ 写的。我们可以使用 Python 来安装并使用 OpenVINO。
显然,开始之前,要有 Python3 和 pip:
sudo apt update
sudo apt install python3 python3-pip
接下来,我使用 python virtualenv 来创建一个虚拟环境。考虑到我的设备太新了,我直接用 Nightly 版本:
python3 -m venv openvino_nightly_env
source openvino_nightly_env/bin/activate
接下来,我们可以安装 OpenVINO:
export CXXFLAGS="-include cstdint"
pip install --pre -U openvino-genai --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
接下来,安装 OpenVINO 的依赖包括 ONNX, Optimum 等。
pip install -U onnx
pip install -U openvino
pip install -U "optimum[openvino]"
语法 "optimum[openvino]" 中的中括号是 Python 包的 extras 语法,用来指定可选的依赖或附加功能。也就是说安装 optimum 包自身的同时,还会额外把与 openvino 相关的可选依赖一并安装上。
使用 OpenVINO
类似 CUDA,在安装 OpenVINO 之后,我们也需要先验证 OpenVINO 是否能过找到 NPU。
在刚刚创建的虚拟环境中,我们可以使用 Python 来验证。运行 python,然后输入以下代码:
# 检查可用设备
from openvino import Core
core = Core()
print("Available devices:", core.available_devices)
# 输出中应包含你期望使用的设备(例如 "NPU")
在我这里,输出的内容是:
['CPU', 'GPU', 'NPU']
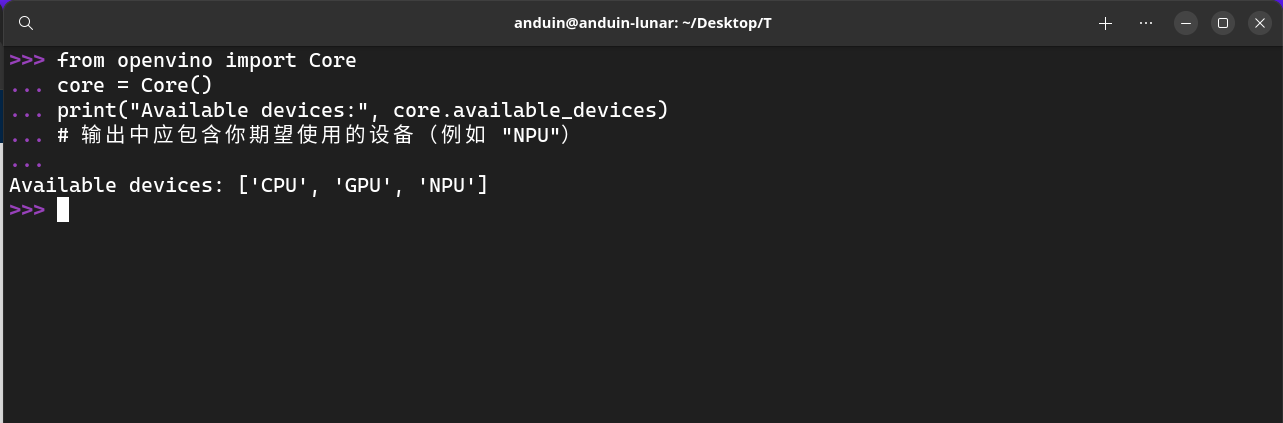
这说明 OpenVINO 已经找到了 NPU。
接下来,我们需要找到适合我的 NPU 的模型。我的 NPU 只支持 4bit 的模型。我找到了一个适合的模型:AIFunOver/DeepSeek-R1-Distill-Qwen-32B-openvino-4bit。
它的模型地址在 https://huggingface.co/AIFunOver/DeepSeek-R1-Distill-Qwen-32B-openvino-4bit。
根据它的介绍:
This model is a quantized version of deepseek-ai/DeepSeek-R1-Distill-Qwen-32B and is converted to the OpenVINO format. This model was obtained via the nncf-quantization space with optimum-intel. First make sure you have optimum-intel installed:
它已经帮我量化好了,并且适合 OpenVINO。我们可以直接使用这个模型。
当然,如果不喜欢用Huggingface上别人量化的,也可以自己转成 OpenVINO:https://docs.openvino.ai/2024/openvino-workflow/model-preparation/convert-model-to-ir.html
from transformers import AutoTokenizer
from optimum.intel import OVModelForCausalLM
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# 模型和 tokenizer 的名称
model_id = "AIFunOver/DeepSeek-R1-Distill-Qwen-32B-openvino-4bit"
model = OVModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 设置 pad_token 为 eos_token 以消除警告
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 配置模型使用 NPU,并编译模型
model.ov_config["device"] = "NPU"
compiled_model = model.compile()
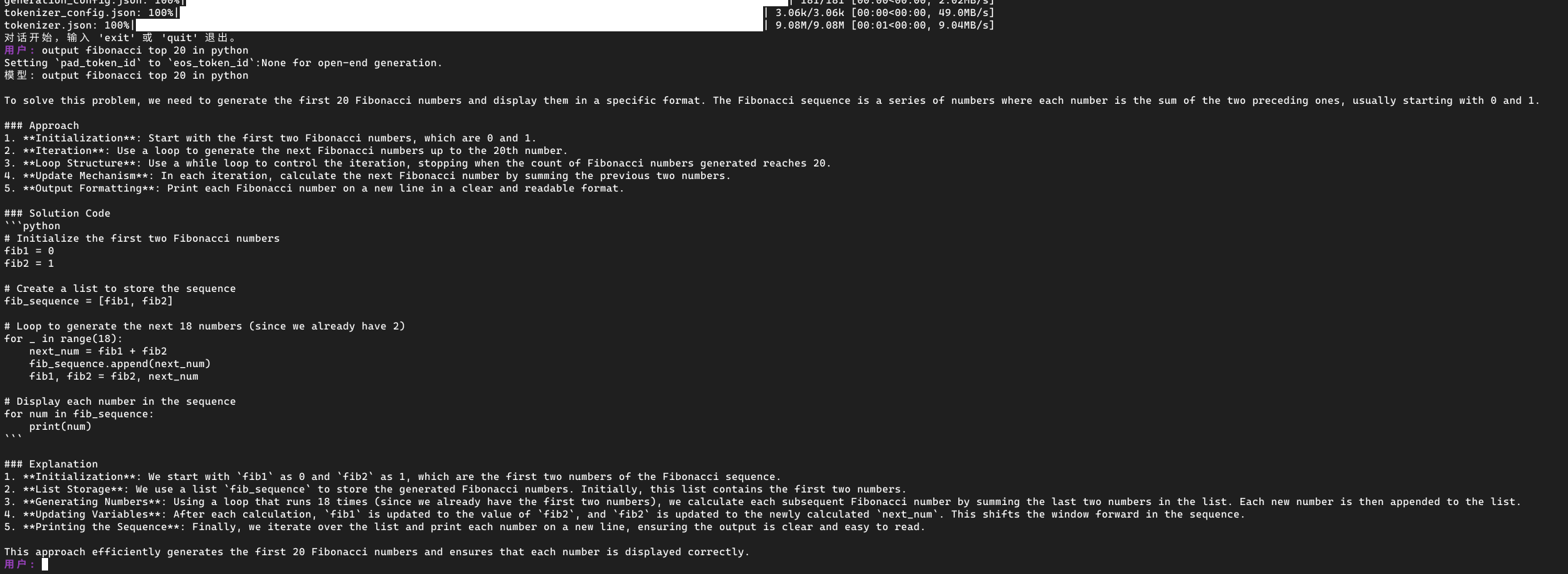
print("对话开始,输入 'exit' 或 'quit' 退出。")
while True:
prompt = input("用户: ").strip()
if prompt.lower() in ("exit", "quit"):
break
inputs = tokenizer(prompt, return_tensors="pt")
generated_ids = model.generate(
inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=5000
)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print("模型:", response)
这个代码会启动一个对话,你可以和 DeepSeek 对话了。
经过测试,它比 CPU 要快很多。(不过说真的也没快到哪去)
这篇文章内容详实,结构清晰,展示了作者对技术实践的深入探索和分享精神。以下从多个维度进行评价:
核心价值与创新点
文章最突出的价值在于填补了NPU与LLM结合应用的实践空白。作者通过具体实验验证了Intel Ultra 7 NPU对DeepSeek 32B模型的可行性,这种"边踩坑边突破"的实证方式具有重要参考价值。特别是对驱动安装、权限配置等易忽视环节的完整记录,为同类硬件用户提供了可复现的路径。代码片段的穿插使用(如权限配置命令和模型验证脚本)极大增强了可操作性,体现了技术写作的务实精神。
技术实现的严谨性
在技术细节处理上表现专业:
render组的权限设置及用户组刷新操作core.available_devices输出设备列表的验证方式规范可改进方向
潜在事实核查点
intel-driver-compiler-npu_1.13.0与Ubuntu 24.10的兼容性验证(文中提到的AnduinOS基于Ubuntu 24.04,但实际使用的是Ubuntu 24.10)延伸建议
文章展现了作者对技术细节的执着和分享精神,建议在后续版本中增加性能基准测试数据和硬件限制说明,使技术方案更具可复现性和推广价值。期待看到更多关于NPU与LLM结合的创新实践。
我的是Intel® Core™ Ultra 7 Processor 258V,win11系统,按官网装了驱动后也识别不出npu,请问可能是哪里的问题
奇怪我的只能识别出来CPU和NPU,却没有GPU支持。Intel Core Ultra 165H
基于上述文章内容,可以总结出以下几点关于在NPU上部署DeepSeek模型的经验和思考:
硬件与软件准备:确保安装了支持NPU的硬件,并配置好相应的驱动程序。同时,需要安装OpenVINO工具包以及相关的Python库如Transformers、Optimum等,这些是后续模型部署的基础。
量化处理的重要性:文章中提到使用的模型已经进行了量化处理,这使得原本较大的模型能够适应NPU的4位计算能力。量化不仅减少了模型的体积,还显著提升了推理速度。
模型验证与设备检测:在代码示例中,通过OpenVINO的核心接口检查可用设备,并确保NPU被识别到,这是确认硬件配置正确的重要步骤。
性能对比与预期管理:虽然文章提到使用NPU比CPU快很多,但实际体验可能因具体模型和任务而异。因此,在部署前进行基准测试是有必要的,以明确是否符合预期的性能提升。
代码实现细节:在加载模型和tokenizer时需要注意一些细节,比如设置pad_token为eos_token以避免警告信息。此外,正确配置模型使用的设备(如NPU)并编译模型也是确保顺利运行的关键步骤。
用户体验与优化:对话生成部分使用了max_new_tokens参数来控制输出长度,这在实际应用中需要根据具体需求进行调整。同时,添加输入退出命令(如"exit"或"quit")可以提升用户交互的友好性。
综上所述,这篇文章提供了一套完整的从环境搭建到模型部署再到性能评估的流程指南。对于希望利用NPU加速AI推理的开发者来说,这是一个非常实用的参考。未来的工作中,可以进一步探索不同量化策略对模型性能的影响,以及优化生成对话的质量和效率。