What is ZFS
ZFS is a modern file system with many features. Some of the important features include:
Copy-on-write: When modifying a file, ZFS first copies the data being modified and then performs the modification. This ensures data integrity.
Redirect-on-write: When writing new data, ZFS writes the new data to a new location instead of overwriting the existing data. This protects the integrity of the original data and improves write efficiency.
Deduplication: When multiple files have the same data blocks, ZFS only keeps one copy of the data block on the storage device, saving storage space.
Snapshots: ZFS can take snapshots of the file system at a specific point in time, recording the state of the file system. This allows for easy restoration to a previous state and can also be used for data backup and recovery.
Compression: ZFS supports on-the-fly compression of data, which can save storage space and improve performance by reducing the amount of data that needs to be read from or written to the storage device.
Caching: ZFS has a built-in cache mechanism called the Adaptive Replacement Cache (ARC) that can improve read performance by keeping frequently accessed data in memory. Additionally, ZFS also supports the use of separate cache devices such as solid-state drives (SSDs) to further improve performance.
RAID: ZFS supports multiple RAID levels, including RAID 0, RAID 1, RAID 5, RAID 6, and RAID 10. These RAID levels can be used to improve performance and/or provide data redundancy.
Storage pools: ZFS uses storage pools to manage storage devices. A storage pool can consist of one or more storage devices, and the storage capacity of the pool is shared between all devices in the pool. This allows for easy expansion of storage capacity by adding more devices to the pool.
Data integrity: ZFS uses checksums to ensure data integrity. When reading data from a storage device, ZFS verifies the checksum of the data to ensure that it has not been corrupted. If the checksum does not match, ZFS will attempt to repair the data by reading it from another device in the pool.
Data scrubbing: ZFS can periodically scan the storage devices in a pool to detect and repair data corruption. This helps to ensure that data is not corrupted over time.
These features make ZFS a powerful and reliable file system suitable for large-scale storage and data management scenarios.
Common knowledge
Pool
In the world of ZFS, everything is based on storage pools. First, you need to create a storage pool for one or more hard drives. The storage pool manages the disks and provides storage space. The capacity is not shared between multiple storage pools.
Forget about RAID! Even you may have a RAID controller, ZFS still expect that you expose all physical disks to a pool!
Set
On top of the storage pools, we can create multiple datasets. Datasets do not require allocated space, which means each dataset can utilize the entire storage capacity of the pool. A dataset must belong to one and only one storage pool.
After creating a dataset, it is mapped as a directory. This allows you to store and organize files and subdirectories within the dataset. For example, if you create a dataset called "photos", you can map it to a directory like /mnt/pool/photos. You can then create subdirectories within this directory to organize your photos. This makes data organization and management more flexible and convenient.
Commands
Installation
To install basic utilities, run:
sudo apt install zfsutils-linux
Use some basic tools like lsblk and fdisk to locate your disk.
Getting context
List sets:
# zfs list
List pools:
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
my_pool 47.5G 387K 47.5G - - 0% 0% 1.00x ONLINE -
# zpool status
pool: my_pool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
my_pool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
errors: No known data errors
Also if you want to check the io status, use zpool iostat:
# zpool iostat -v
Managing Pools
- Use one disk to create one pool
- Use multiple disks to create one pool
- Use one disk to create multiple pools
You can create a new pool with command (Use one disk):
# zpool create my_pool /dev/sda # <--- /dev/sda is your physical disk!
To create multiple pools with one disk(NOT suggested):
# zpool create my_pool /dev/sda1 # <--- /dev/sda1 is your partition. This is NOT suggested because the capacity was not shared between pools!
Of course, you can use multiple devices to create one pool:
# zpool create my_pool raidz /dev/sdb /dev/sdc # At least 2 disks
# zpool create my_pool raidz2 /dev/sdb /dev/sdc # At least 3 disks
# zpool create my_pool raidz3 /dev/sdb /dev/sdc # At least 4 disks
That also creates a ZFS level Raid called Raid-Z.
You may need a calculator for planning ZFS.
If you bought new disks and want to add the new disk to your existing pool, that's also possible!
zpool add my_pool /dev/new
# zfs set quota=new_size my_pool
Note that expanding ZFS pools takes some time, depending on the size and number of devices you are adding. During the expansion of the pool, you can still use the data in the pool, but you may experience a performance decrease.
Managing Sets
To create and mount:
# zfs create pool/set
# zfs set mountpoint=/test pool/set
To delete a set:
# zfs destroy -r pool/set
Features
Data dedup
You can use the deduplication (dedup) property to remove redundant data from your ZFS file systems. If a file system has the dedup property enabled, duplicate data blocks are removed synchronously. The result is that only unique data is stored, and common components are shared between files.
Pool level
# zfs get dedup pool
# zfs set dedup=on pool
Or set level:
# zfs get dedup pool/set
# zfs set dedup=on pool/set
Use zpool list to check the dedup ratio.

You may also want to check the total size may change:
root@lab:/my_pool# df -Th
Filesystem Type Size Used Avail Use% Mounted on
my_pool zfs 18G 3.0G 15G 18% /my_pool
Right here,
(Right here, '=' means equals not assignment)
Available space left = ZFS total storage capacity - Raw used space
Available space left = Logical usable storage capacity - Logical used space
Logical usable storage capacity = Available space left + Logical used space
Logical usable storage capacity = ZFS total storage capacity - Raw used space + Logical used space
In the world of ZFS, if you enable data deduplication, you will find that the total space of the dataset from df command is dynamically changing.
- Total raw storage capacity: 48G
- Raid Level: RaidZ2
- ZFS usable storage capacity: 16G
- Logical used space: 3G
- Raw used space: 1G
- Dedup ratio: 3x
- Dedup ratio = Logical used space / Raw used space
- Logical usable storage capacity: Dynamic calculated: 18G
- Logical usable storage capacity = ZFS usable storage capacity + (Logical used space - Raw used space)
- Available space left: 15G
- Available space left = ZFS total storage capacity - Raw used space
- Available space left = Logical usable storage capacity - Logical used space
Snapshot
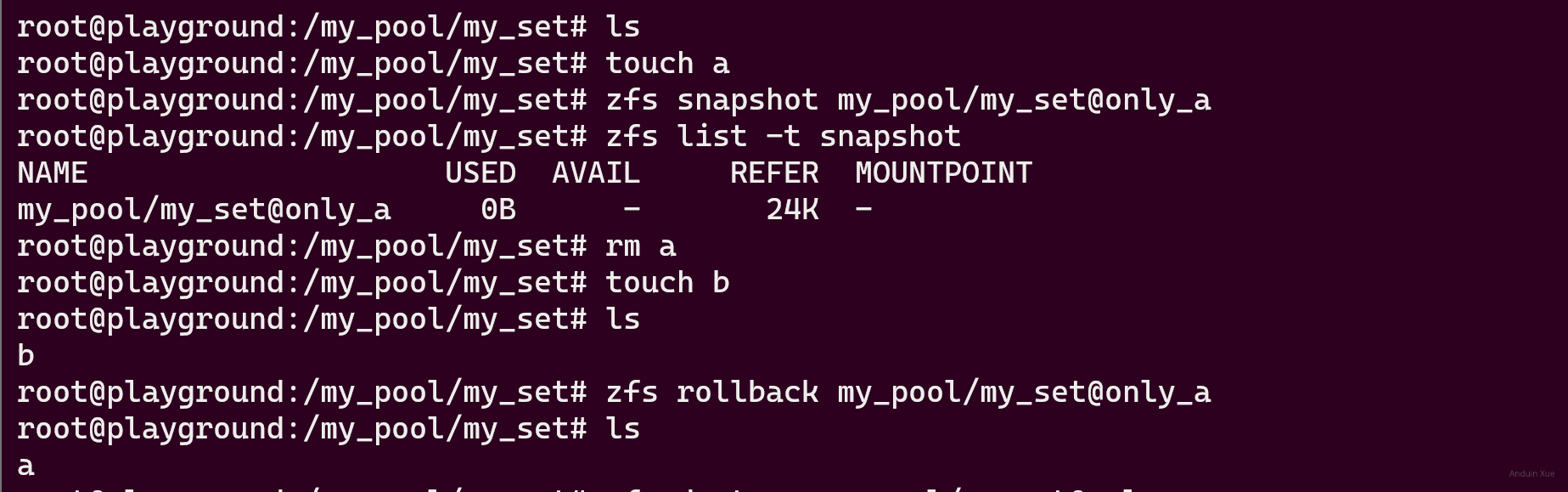
Create snapshot:
# zfs snapshot pool/set@name
List snapshots:
# zfs list -t snapshot
Rollback to snapshot:
# zfs rollback pool/set@name
Rollback is Dangerous! It may delete the status between current and the snapshot! Use clone instead:
# zfs clone pool/set@name pool/set2
That will clone the snapshot as a dataset.
Delete snapshot:
# zfs destroy pool/set@name
Compression
By default, compression is disabled:
# zfs get compression my_pool
To enable it:
# zfs set compression=lz4 my_pool
lz4 is a very fast compression algorithm that has very little CPU overhead, so it's a good choice if you want to maximize performance. It's also the default compression algorithm used by ZFS on most systems.
You can also use gzip or zle. Compare with lz4, gzip is slower but has a higher compression ratio, while zle is faster but has a lower compression ratio.
# zfs set compression=gzip my_pool
# zfs set compression=zle my_pool
The impact of enabling lz4 on performance needs to be analyzed on a case-by-case basis. Enabling lz4 is like making some disk reading tasks simpler: just read the compressed data and have the CPU decompress it. The problem is that large-scale decompression may consume CPU performance, although it takes up very little. Therefore, lz4 can significantly improve performance in situations where the CPU is strong and there is a lot of redundant disk data. However, lz4 may not necessarily improve performance when the CPU is weak and almost all disk data is already compressed.
To query current compress ratio:
# zfs get compressratio my_pool
Caching
ZFS has a built-in caching mechanism called Adaptive Replacement Cache (ARC) to improve read performance. ARC is a dynamic cache that automatically adjusts its size based on the system's memory usage. It stores frequently accessed data in memory so that the system can access it quickly.
ZFS also supports the use of separate caching devices, such as solid-state drives (SSDs), to further improve performance. These caching devices are called ZFS Intent Log (ZIL) and ZFS Cache (L2ARC). ZIL is used to improve the performance of synchronous writes, while L2ARC is used to improve the performance of read operations.
Using separate caching devices can significantly improve performance in situations where system memory is limited or the workload is particularly read-intensive. However, using caching devices may also increase the cost of the storage system, so the benefits and costs need to be considered before implementing them.
For exmaple, to use two Samsung NVME solid-state drives as ZFS cache devices, which can significantly improve read and write performance:
Firstly, you need to allocate these two NVME solid-state drives to ZFS Intent Log (ZIL) and Level 2 Adaptive Replacement Cache (L2ARC) respectively.
To allocate an NVME solid-state drive to ZIL, use the following command:
# zpool add my_pool log nvme0n1
Here, my_pool is your ZFS pool name, and nvme0n1 is your NVME solid-state drive device name.
To allocate an NVME solid-state drive to L2ARC, use the following command:
# zpool add my_pool cache nvme1n1
Here, my_pool is your ZFS pool name, and nvme1n1 is your NVME solid-state drive device name.
After allocating the NVME solid-state drive to ZIL and L2ARC, you can use the following command to view the status of the ZFS pool:
# zpool status my_pool
Usually, for a 16GB pool, the suggested ZIL size is 4GB, and the suggested L2ARC size is 4GB.
To check details:
# cat /proc/spl/kstat/zfs/arcstats
RAID
ZFS supports multiple RAID levels, including RAID 0, RAID 1, RAID 5(Z), RAID 6(Z2), and RAID 10. These RAID levels can be used to improve performance and/or provide data redundancy.
To create a RAID 0 pool, use the following command:
# zpool create my_pool /dev/sda /dev/sdb
Here, my_pool is your ZFS pool name, and /dev/sda and /dev/sdb are your hard drive device names.
To create a RAID 1 pool, use the following command:
# zpool create my_pool mirror /dev/sda /dev/sdb
Here, my_pool is your ZFS pool name, and /dev/sda and /dev/sdb are your hard drive device names.
To create a RAID 5 pool, use the following command:
# zpool create my_pool raidz /dev/sda /dev/sdb /dev/sdc
Here, my_pool is your ZFS pool name, and /dev/sda, /dev/sdb, and /dev/sdc are your hard drive device names.
To create a RAID 6 pool, use the following command:
# zpool create my_pool raidz2 /dev/sda /dev/sdb /dev/sdc /dev/sdd
Here, my_pool is your ZFS pool name, and /dev/sda, /dev/sdb, /dev/sdc, and /dev/sdd are your hard drive device names.
Scrubbing
ZFS can periodically scan the storage devices in a pool to detect and repair data corruption. This helps to ensure that data is not corrupted over time.
To start a scrub, use the following command:
# zpool scrub my_pool
Here, my_pool is your ZFS pool name.
To view the status of a scrub, use the following command:
# zpool status my_pool
To stop a scrub, use the following command:
# zpool scrub -s my_pool
Integrity
ZFS uses checksums to ensure data integrity. When reading data from a storage device, ZFS verifies the checksum of the data to ensure that it has not been corrupted. If the checksum does not match, ZFS will attempt to repair the data by reading it from another device in the pool.
To enable checksums, use the following command: (Enabled by default)
# zfs set checksum=on my_pool
My configuration example
Here is my configuration example:
# Create a pool with 12 disks
sudo zpool create -o ashift=12 pool raidz2 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120 \
/dev/disk/by-id/ata-TOSHIBA_HDWD120
# Set some properties
sudo zfs set compression=lz4 recordsize=1M xattr=sa dnodesize=auto pool
# Create a dataset
sudo zfs create -o mountpoint=/mnt/pool pool/data
# Add cache and log
sudo zpool add pool cache nvme0n1
sudo zpool add pool log nvme1n1
# Disable sync and atime for performance
sudo zfs set sync=disabled pool
sudo zfs set atime=off pool
这篇文章对ZFS的配置和管理进行了系统性梳理,内容详实且结构清晰,尤其在实践操作和理论结合方面表现出色。以下几点值得肯定与探讨:
实践指导性强
通过"快照回滚与克隆"、"RAID配置示例"等章节,将抽象概念转化为具体命令(如
zpool add my_pool cache nvme0n1),便于读者直接复用。特别是"我的配置示例"部分,展示了ashift、recordsize等参数的组合应用,这种真实场景的呈现能帮助用户理解配置逻辑。技术细节的深度平衡
在解释压缩算法时,不仅列出lz4/gzip/zle的差异,还通过"CPU性能与数据冗余度的权衡"分析其适用场景,这种定量分析(如"16GB池建议4GB ZIL")比单纯罗列参数更具指导意义。但关于
sync=disabled和atime=off的性能优化,可补充其风险说明(如数据一致性保障机制)。可优化的表述方式
潜在改进方向
iostat、zpool iostat等工具的使用示例,帮助用户验证配置效果。zpool replace),增强实战价值。创新性建议
在"去重比"章节,可引入
zdb命令分析实际存储碎片情况,通过可视化数据(如zdb -d my_pool输出)展示不同压缩算法对存储效率的影响,使理论分析更具说服力。总体而言,这篇文章为ZFS用户提供了从基础配置到高级优化的完整知识图谱,若能在关键节点增加风险提示和监控手段,将更符合生产环境应用的需求。期待后续对ZFS扩展特性(如NFS/SMB集成)的深入探讨。
这篇文章详细介绍了ZFS存储池的配置与优化技巧,内容非常丰富,涵盖了压缩、缓存加速、RAID配置、数据完整性以及性能优化等多个方面。以下是我对这些内容的一些思考和建议:
压缩功能
文章提到使用
lz4作为压缩算法,并且强调了其高性能和高效性。确实,在存储系统中启用压缩可以显著节省空间,尤其是在处理大量文本或可压缩的二进制文件时。不过,值得注意的是,选择压缩算法也需要根据具体的工作负载来决定。例如,如果数据本身已经是高度压缩的(如视频或图片),使用lz4可能不会带来明显的收益。此外,是否启用压缩还需要权衡CPU资源的消耗,因为压缩会占用一定的计算资源。缓存加速
文章中提到通过添加NVMe设备作为缓存和日志来提升性能,这是一个非常明智的选择。缓存设备可以显著加快随机读取速度,而将日志放在高性能存储设备上也可以提高写入性能。不过,在实际应用中,需要仔细监控缓存的使用效率。如果发现缓存命中率较低,可能需要调整数据访问模式或优化缓存策略。
RAID 配置
文章中的RAID配置选择了
raidz2,这是一种高可靠性的选择,能够容忍两块磁盘同时故障。对于企业级存储系统来说,这种冗余设计非常重要。不过,在实际部署中,还需要考虑磁盘的物理布局和热备盘的设置,以进一步提高系统的可用性。此外,raidz3也是一个可以考虑的选择,特别是当磁盘数量较多时,它可以提供更高的冗余能力。数据完整性和性能优化
文章提到通过禁用同步 (
sync=disabled) 和访问时间记录 (atime=off) 来提升性能,这在某些高性能存储场景中非常有用。不过,需要注意的是,这些设置可能会对数据的完整性检查和文件系统的元数据产生影响。例如,atime=off会减少文件系统元数据的更新频率,从而降低I/O负载,但这也意味着无法记录文件的实际访问时间。因此,在启用这些优化之前,需要权衡性能提升与功能损失之间的关系。维护策略
文章提到了定期进行存储池的scrubbing(扫描和修复),这是一个非常重要的维护步骤。通过scrubbing,可以检测并修复潜在的数据错误,从而确保数据的长期完整性。建议在生产环境中设置自动化任务,定期执行scrubbing操作,并监控其结果,以便及时发现和处理问题。
总结
这篇文章为读者提供了一个全面的ZFS配置指南,涵盖了从基本设置到高级优化的各个方面。对于想要深入理解并优化存储系统的用户来说,这些内容非常有参考价值。不过,在实际应用中,还需要根据具体的业务需求和硬件环境进行调整和测试,以达到最佳性能和可靠性。
This blog post does a great job of explaining how to use the ZFS file system. The author clearly outlines the key features of ZFS, such as copy-on-write, redirect-on-write, deduplication, and snapshots, and explains why these features make ZFS a powerful and reliable choice for large-scale storage and data management scenarios.
The author's explanation of how storage pools and datasets work in ZFS is particularly useful. The use of concrete examples, such as creating a dataset called "photos" and mapping it to a directory, helps to clarify these concepts and makes the post accessible to readers who may not be familiar with file systems.
The blog post also provides detailed instructions on how to install and use ZFS, including how to create and manage storage pools and datasets, how to enable deduplication, and how to create, list, rollback, clone, and delete snapshots. These instructions are clear and easy to follow, and the inclusion of command line examples is very helpful.
However, the blog post could be improved by providing more context and explanation for some of the commands. For example, the author mentions that creating a pool with multiple devices creates a ZFS level Raid called Raid-Z, but does not explain what Raid-Z is or why a user might want to use it. Similarly, the author warns that rolling back to a snapshot is dangerous and suggests using clone instead, but does not explain why this is the case or what the potential risks are.
The author could also consider adding a section on troubleshooting common issues with ZFS. This would make the blog post even more useful for readers who are new to ZFS and may encounter problems when trying to use it for the first time.
Overall, this is a very informative and useful blog post that does an excellent job of explaining how to use ZFS. With a few minor improvements, it could be an invaluable resource for anyone interested in large-scale storage and data management.