讨论时,这里首先提出一个非常有趣的问题:操作系统和应用程序,是谁先诞生,谁后诞生呢?
这是我在本科期间学习计算机时,经常思考的一个问题。
它看起来答案是显而易见的:应用程序运行于操作系统之上,那自然是操作系统先诞生。但是,这个问题的答案并不是那么简单。甚至回答它,你才能理解计算机和操作系统的本质,才能理解为什么今天也要学习汇编、C语言、操作系统等等。
排除掉一些无意义的纠结
很多人会纠结这个问题本身里,“应用程序”的定义。他们纠结于:一个不依赖操作系统,就能产生功能的设备,例如计算器,它的程序是不是应用程序?
根据牛津词典中对 "Application" 的定义: Application is a computer program designed for a particular purpose. 只要是用于解决特定问题的计算机程序,都可以称之为应用程序。
无论是阿波罗的导航系统,亦或是空客的飞控计算机,亦或是手机里的短视频,甚至终结者里的 T-800,他们都在运行着由算法和数据结构组成的计算机程序,并且解决着特定的问题。所以,它们都可以算是符合 Application 的定义的。
问题本身带来的悖论?
操作系统和应用程序,哪个先诞生?哪个后诞生?
当然,就像很多人不假思索的说出:应用程序运行于操作系统之上,那自然是操作系统先诞生。同样,也会有人指出:操作系统是为了运行应用程序而诞生的,所以应用程序先诞生。
在今天,如果你新发布一个 Linux 发行版,它天生就可以运行几乎所有 Linux 的应用程序。显然,它诞生晚于应用程序。而今天,如果你发布了鸿蒙操作系统,你又需要在系统做好时,赶紧号召开发者为你的新系统开发软件。显然,它诞生晚于应用程序。
难道这个问题本身会带来悖论吗?为什么人们对这个问题总是吵个不停?
但是,在展开思考之前,我们需要先看看最早期的计算机和汇编语言。
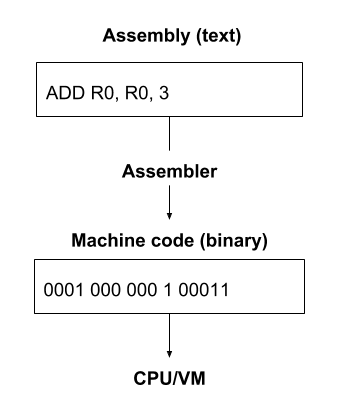
汇编语言与程序组成
在展开思考之前,我们需要先看看汇编语言。
阅读下面的代码:
#include <stdio.h>
struct Point {
int x;
int y;
};
void print_point(struct Point p) {
printf("Point(%d, %d)\n", p.x, p.y);
}
int main() {
struct Point p = {1, 2};
print_point(p);
return 0;
}
我用 gcc 编译这段代码并生成汇编代码时,可以看到如下内容:
.section .data
.LC0:
.string "Point(%d, %d)\n"
.section .text
.globl print_point
print_point:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
movl %eax, %edi
movl -8(%rbp), %eax
movl %eax, %esi
movl $.LC0, %eax
movq %rax, %rdi
movl $0, %eax
call printf
leave
ret
.globl main
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl $1, -4(%rbp)
movl $2, -8(%rbp)
movl -4(%rbp), %edi
movl -8(%rbp), %esi
call print_point
movl $0, %eax
leave
ret
这段汇编代码中,我们可以清晰地看到数据段和代码段的区别:
.data段:用于存储全局变量和字符串常量。在这个例子中,.LC0是一个字符串常量 "Point(%d, %d)\n"。.text段:用于存储代码。在这个例子中,包括print_point函数和main函数的实现。
别忘了,这些最终会变成二进制,整齐的排列在内存、硬盘里,每一行都是有自己的地址的。通过这个例子,我们可以看到,编译器将 C 语言代码转换成汇编代码时,生成了两个主要的段:数据段和代码段。数据段包含了程序运行时需要的全局变量和常量,而代码段则包含了程序的指令。无论是数据段还是代码段,都有自己的地址。从内存的视角来看,都是数据。
.section .data
.LC0:
0x1000 .string "Point(%d, %d)\n"
.section .text
.globl print_point
print_point:
0x1010 pushq %rbp
0x1014 movq %rsp, %rbp
0x1018 subq $16, %rsp
0x101C movl %edi, -4(%rbp)
0x1020 movl %esi, -8(%rbp)
0x1024 movl -4(%rbp), %eax
0x1028 movl %eax, %edi
0x102C movl -8(%rbp), %eax
0x1030 movl %eax, %esi
0x1034 movl $.LC0, %eax
0x1038 movq %rax, %rdi
0x103C movl $0, %eax
0x1040 call printf
0x1044 leave
0x1048 ret
.globl main
main:
0x1050 pushq %rbp
0x1054 movq %rsp, %rbp
0x1058 subq $16, %rsp
0x105C movl $1, -4(%rbp)
0x1060 movl $2, -8(%rbp)
0x1064 movl -4(%rbp), %edi
0x1068 movl -8(%rbp), %esi
0x106C call print_point
0x1070 movl $0, %eax
0x1074 leave
0x1078 ret
如何调试汇编的
在继续介绍之前,我还想提前分享分享我最开始是如何学汇编的。
汇编语言不同于我们学过的任何一门语言。汇编直接与CPU硬件指令集打交道。只需要非常简单的翻译就算是“编译”了。
汇编的概念是早于操作系统的。所以,自然我写的汇编……我就不想在操作系统里运行。它明明操作的是 CPU,我干的活可是在寄存器之间搬来搬去。我们如果能够直接让 CPU 执行才是真的理解了汇编。而不是学习其他语言那些面对 IDE。
当然,我自己的电脑,寄存器,被我万一搬坏了怎么办……
使用虚拟机调试汇编代码是一种有效且安全的方法,我们可以将编辑好的汇编程序当作一个虚拟磁盘,直接刷入MBR主引导记录,然后启动虚拟机,它就会执行这些汇编指令。
虚拟机提供了一个隔离的沙盒环境,并且这个沙盒里有虚拟的 CPU 和寄存器,非常容易调试。
在虚拟机启动以后,我就彻底掌控了这颗芯片了!它的每一个动作都是我的指令。
https://stackoverflow.com/questions/13021466/using-a-virtual-machine-to-learn-assembly
上面编译后的汇编代码实际上是 x86 汇编,它并非一直主流。早期不同计算机有各自的汇编语言,如 IBM 的 S/360 和 DEC 的 PDP-11。x86 汇编成为主流始于英特尔在1970年代末推出的 8086 处理器,它兼容8位和16位架构。此后,英特尔的 80286、80386 以及奔腾系列处理器延续了这种兼容性,使得软件能在新处理器上运行。微软的 MS-DOS 和 Windows 操作系统进一步推动了 x86 汇编的普及。与其他早期汇编语言相比,x86 的市场支持和兼容性优势使其成为主流。
我们今天的编译器都是将高级语言编译成低级语言。例如,C语言代码会被编译成汇编代码,再由汇编代码编译成机器码。
机器码是硬件芯片唯一能直接执行的指令集。
在1950年代,Grace Hopper开发了第一个编译器A-0,使得用英语样的语句来编写程序成为可能,而不是用复杂的机器码。编译器的出现大大简化了编程过程,但最终生成的还是需要硬件执行的机器码。这说明了编译器的核心作用:将人类可读的高级语言转化为计算机可执行的机器码,从而实现程序的运行。
别忘了,上面的例子告诉我们,即使没有操作系统,我们也可以开发和运行运行程序,只要将机器码直接加载到内存并让CPU执行。
上面的例子也告诉我们,即使没有操作系统,我们也可以开发和运行运行程序。很多大学的操作系统课程作业,正是让学生使用汇编,在虚拟机中运行,看到汇编的执行结果。
在早期的计算机中,程序员直接在控制面板上设置二进制开关,输入机器码,然后启动程序。现代的微控制器也是如此,它们无需操作系统,只需将编译好的机器码写入闪存即可运行。在我讨论这一切的时候,还没有引入操作系统的概念。
操作系统的诞生

https://en.wikipedia.org/wiki/PDP-7
上面提到的传统开发模式流行了很久,直到20世纪60年代,人们才开始意识到计算机需要更有效的管理和操作方式。那时,许多研究人员和工程师为了运行特定的程序,必须为每个程序编写特定的控制代码。1969 年,Ken Thompson 想在 PDP-7 计算机上运行“Space Travel”游戏,于是他徒手搓了一个能管理内存的小东西跑他的小游戏。
早期的计算机,如 IBM 704,使用体验非常痛苦,因为每次运行新程序都需要重新配置机器。为了提高效率,科学家们开发了批处理系统,实现了程序的自动加载和顺序运行。然而,对于计算机这种关键科研设备的争抢仍然非常激烈。实验室只能安排工程师排队使用计算机。很多低优先级长时间的任务非常浪费硬件资源。
随着分时复用和虚拟内存技术逐渐出现,允许多个程序共享硬件资源并独立运行,避免了互相干扰。通过进程隔离和内存管理,操作系统的概念逐渐明朗,成为现代计算机系统的核心,保障了多任务环境下的资源分配和安全性。

{kind=link}
在麻省理工学院的研究中,CTSS(Compatible Time-Sharing System)是一个重要的里程碑。CTSS 是第一个真正的分时操作系统,允许多个用户同时在一台计算机上工作。这一系统的开发进一步推动了多任务操作系统的发展,为现代操作系统奠定了基础。直到这时,操作系统的概念才逐渐清晰,并开始成为计算机科学的一个重要研究领域。
操作系统的基本概念之一是进程。进程是一个正在运行的程序的实例,它包含了程序的代码以及当前活动的状态信息,如寄存器内容和内存中的数据。进程管理是操作系统的重要职责之一,它确保多个进程能够在同一个系统上高效、安全地运行。
虽然操作系统在进程管理中扮演了重要角色,但需要注意的是,进程实际执行时,指令仍然是由 CPU 直接执行的。操作系统并不会在每条指令之间进行翻译或插手,而是通过调度机制来管理进程的执行顺序和资源分配。进程本身就是程序,它们就是面向 CPU 的机器码。操作系统没有职责去真正计算进程的执行结果,而只管理了CPU的时间和管理进程的生命周期。
举个例子,可以联想到我们日常使用的计算机中运行的多个应用程序。假设你同时打开了浏览器、游戏和音乐播放器,这三个应用程序对应着三个不同的进程。操作系统通过进程调度来决定哪个进程在何时占用 CPU 时间片,从而实现多任务处理。即使你的游戏战斗非常激烈,音乐播放器也能保持流畅播放,这得益于操作系统的进程管理和调度。对于操作系统而言,它绘制了一个非常美好的图景,让你认为好像有些程序在“后台运行”。但实际上,所有的程序都是直接运行在 CPU 上的,“后台运行”的程序也在特定时刻占用了 CPU 的时间片。
回顾上面的 C 语言代码
回顾上面的 C 语言代码,我们可以进一步探讨指向函数的指针及其在运行时的内存操作。指向函数的指针不仅仅是一个数据类型,它实际上代表了在程序运行时的一个执行点。这个执行点可以被动态地指定和调用,这种灵活性对于操作系统和应用程序的关系有着深远的意义。
首先,我们来看一个简单的例子,如何使用指向函数的指针:
#include <stdio.h>
void hello() {
printf("Hello, World!\n");
}
int main() {
void (*func_ptr)();
func_ptr = hello;
printf("Address of function hello: %p\n", hello);
printf("Address stored in func_ptr: %p\n", func_ptr);
func_ptr();
return 0;
}
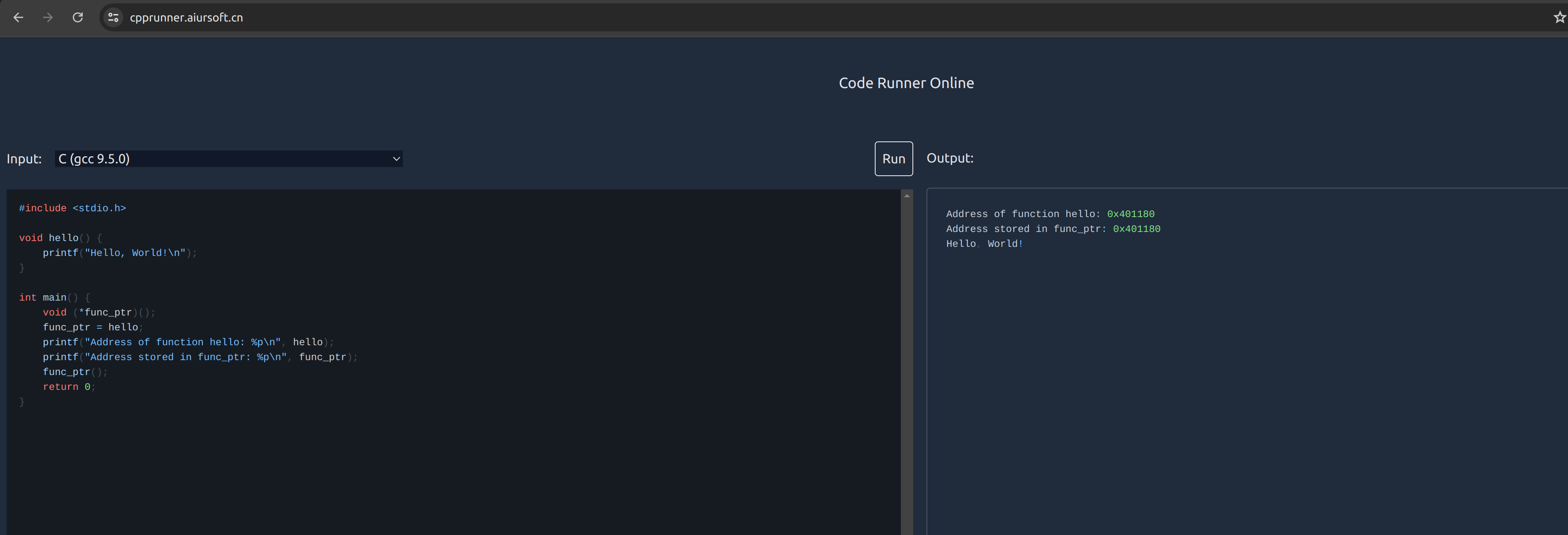
在这个例子中,我们定义了一个函数 hello,并且在 main 函数中声明了一个指向函数的指针 func_ptr。然后我们将 func_ptr 指向 hello 函数,并通过 func_ptr 调用了 hello 函数。这展示了函数指针如何指向代码段中的一个特定函数,并通过指针来调用这个函数。
接下来,我们可以进一步探讨如何将一个可执行的二进制程序复制到内存并运行它。假设我们有一个二进制程序文件 program.bin, 它可能是这么来的:
gcc -c -o program.o program.c
objcopy -O binary program.o program.bin
我们可以通过如下代码实现这个操作:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void load_and_execute(const char *filename) {
FILE *file = fopen(filename, "rb");
if (!file) {
perror("Failed to open file");
exit(EXIT_FAILURE);
}
// 获取文件大小
fseek(file, 0, SEEK_END);
long filesize = ftell(file);
fseek(file, 0, SEEK_SET);
// 分配内存并读取文件内容
char *buffer = malloc(filesize);
if (!buffer) {
perror("Failed to allocate memory");
fclose(file);
exit(EXIT_FAILURE);
}
fread(buffer, 1, filesize, file);
fclose(file);
// 定义一个函数指针并指向加载到内存中的代码段
void (*func_ptr)() = (void (*)())buffer;
// 执行加载的程序
func_ptr();
// 释放内存
free(buffer);
}
int main() {
load_and_execute("program.bin");
return 0;
}
在这个例子中,我们定义了一个函数 load_and_execute,该函数接受一个文件名作为参数。首先,它打开指定的二进制文件并获取其大小。然后,它分配足够的内存来存储文件内容,并将文件内容读取到内存中。接下来,我们定义一个函数指针 func_ptr 并将其指向内存中加载的代码段。最后,通过调用 func_ptr 来执行加载的程序。
或者,可以直接执行下面这段代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <unistd.h>
unsigned char add_bin[] = {
// 这里是针对 x86_64 架构的 add 函数的二进制机器码
0x55, // push %rbp
0x48, 0x89, 0xe5, // mov %rsp,%rbp
0x89, 0x7d, 0xfc, // mov %edi,-0x4(%rbp)
0x89, 0x75, 0xf8, // mov %esi,-0x8(%rbp)
0x8b, 0x55, 0xfc, // mov -0x4(%rbp),%edx
0x8b, 0x45, 0xf8, // mov -0x8(%rbp),%eax
0x01, 0xd0, // add %edx,%eax
0x5d, // pop %rbp
0xc3 // retq
};
void load_and_execute() {
// 获取页面大小
size_t pagesize = sysconf(_SC_PAGESIZE);
// 分配可读、可写、可执行的内存页
void *exec_mem = mmap(NULL, pagesize, PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (exec_mem == MAP_FAILED) {
perror("mmap");
exit(EXIT_FAILURE);
}
// 将函数的机器码复制到可执行内存中
memcpy(exec_mem, add_bin, sizeof(add_bin));
// 定义一个函数指针并指向加载到内存中的代码段
int (*add_func)(int, int) = (int (*)(int, int))exec_mem;
// 调用加载的函数
int result = add_func(2, 3);
printf("Result of add(2, 3): %d\n", result);
// 释放内存
if (munmap(exec_mem, pagesize) == -1) {
perror("munmap");
exit(EXIT_FAILURE);
}
}
int main() {
load_and_execute();
return 0;
}
上面这个例子里,我将一段二进制的机器代码直接写在了 C 代码中,使用mmap将其复制到内存,再将一根指针指向它,直接让 CPU 运行,最后用 munmap 释放内存。它竟然真的可以运行并得到结果。
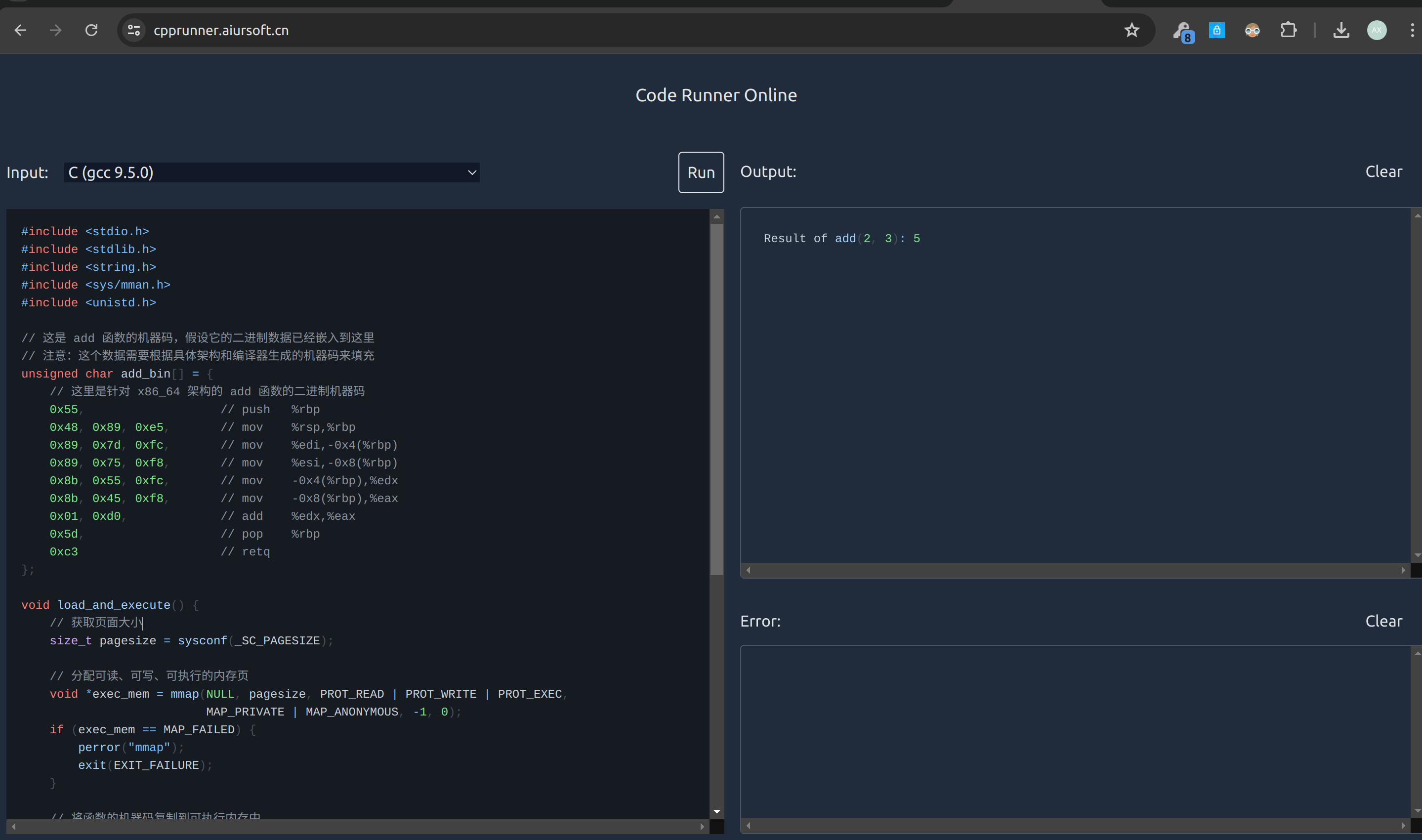
这个例子展示了如何在没有操作系统的情况下加载和执行一个二进制程序。在上面我偷懒,直接将机器码放在了一个 char[] 中。如果是从一个文件中阅读到的这部分内容,会更具有说服力。此时这个文件就算是“可执行文件”了。
实际上,早期的计算机系统就是通过这种方式直接执行程序的。这也解释了为什么理解指向函数的指针以及底层的内存操作对于掌握计算机和操作系统的本质是如此重要。
当我们深入理解了这些底层操作,就可以更好地理解操作系统的设计和实现。操作系统通过管理和调度内存中的各种程序,实现了多任务处理和资源管理。而这些基本操作,如加载和执行二进制程序,正是操作系统运行的核心机制之一。
阶段性总结
操作系统和应用程序,究竟哪个先诞生?
严格来说,是芯片和计算的指令集先诞生,然后应用程序诞生,再然后操作系统诞生。芯片和指令集是计算的基础,它们定义了计算机可以执行的基本操作。
最早的计算机如ENIAC就是通过直接操控硬件来进行计算的,这相当于运行最原始的应用程序。这些应用程序是非常简单的指令序列,完全依赖于硬件,没有任何中间层。后来,随着应用程序变得越来越复杂,操作系统才应运而生。
那么,这个问题的答案真的就是:应用程序先诞生,后来操作系统来解决了一些问题,然后应用程序又发展出了更多的需求,操作系统又解决了更多的问题。这样螺旋式发展,吗?
emmmmmm
在接下来的学习中,我们还得重新回顾回顾本科的知识:
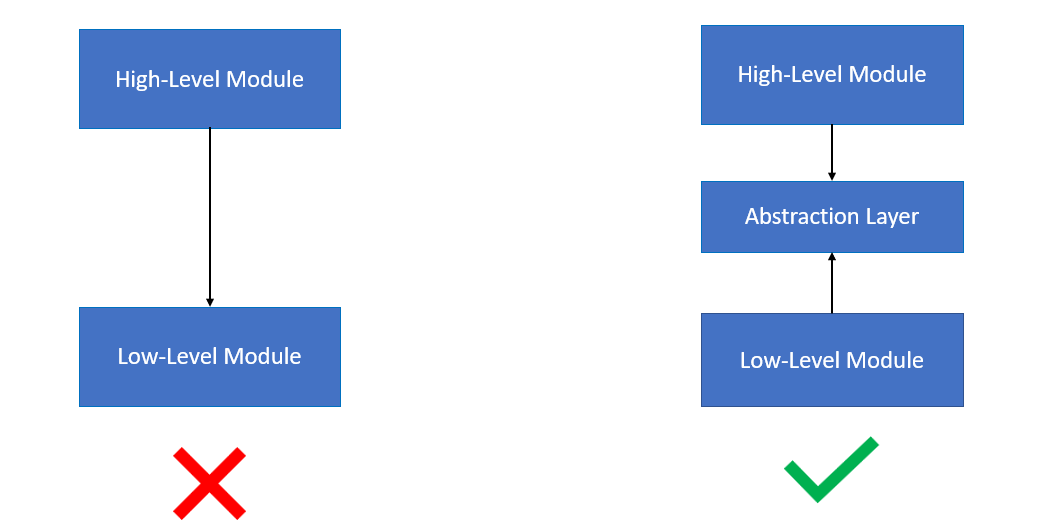
依赖倒置原则
依赖倒置原则是 Robert C. Martin 在其经典著作《敏捷软件开发:原则、模式与实践》中提到的五个面向对象设计原则之一。这个原则强调高层次的模块不应该依赖于低层次的模块,两者都应该依赖于抽象。具体来说,模块之间的依赖关系应尽可能通过抽象(接口或抽象类)来管理,而不是通过具体实现。
让我们通过一个实际的例子来说明这个原则。假设我们要实现一个简单的灯和开关系统。在传统的设计中,开关类直接依赖于灯类:
class Light {
public void turnOn() {
System.out.println("The light is on");
}
public void turnOff() {
System.out.println("The light is off");
}
}
class Switch {
private Light light;
public Switch(Light light) {
this.light = light;
}
public void operate(String command) {
if (command.equals("ON")) {
light.turnOn();
} else if (command.equals("OFF")) {
light.turnOff();
}
}
}
在这个设计中,Switch 类直接依赖于 Light 类,违反了依赖倒置原则。按照依赖倒置原则,我们应该依赖于抽象,而不是具体实现。我们可以定义一个 Switchable 接口,表示任何可以开关的设备:
interface Switchable {
void turnOn();
void turnOff();
}
class Light implements Switchable {
@Override
public void turnOn() {
System.out.println("The light is on");
}
@Override
public void turnOff() {
System.out.println("The light is off");
}
}
class Switch {
private Switchable device;
public Switch(Switchable device) {
this.device = device;
}
public void operate(String command) {
if (command.equals("ON")) {
device.turnOn();
} else if (command.equals("OFF")) {
device.turnOff();
}
}
}
现在,Switch 类依赖于 Switchable 接口,而不是具体的 Light 类。这样我们可以更容易地扩展系统,例如添加一个新的 Fan 类,而不需要修改 Switch 类:
class Fan implements Switchable {
@Override
public void turnOn() {
System.out.println("The fan is on");
}
@Override
public void turnOff() {
System.out.println("The fan is off");
}
}
类似的原则在其他领域也适用。比如在驾校学车时,我们学习的是驾驶一辆机动车,而不是特定的品牌,如特斯拉、奔驰或凯迪拉克。我们学的是一种抽象的技能,这样我们就能驾驶任何品牌的汽车。
再比如,在开发软件时,如果我要使用 Redis,我并不是真的依赖于 Redis 本身,而是依赖于一个键值数据库(KV 数据库)。Redis 是其中的一种实现,我们同样可以使用其他的 KV 数据库,只要它们符合相同的抽象接口。
这一原则的应用还有很多,比如在学习编程时,我们并不是真正要学习 Python、Java 或 C++ 本身,而是学习一种使计算机能够进行一系列计算的表达方法。这些编程语言只是表达方法的一种实现。
通过理解和应用依赖倒置原则,我们可以构建出更加灵活和可扩展的系统。这个原则不仅帮助我们解耦模块,还使得我们的系统更加模块化和易于维护。这就是为什么理解这个原则对软件开发者来说至关重要。
介绍依赖倒置原则,都是为了在软件开发中可以扩展。接着,我们讨论一下软件是怎么扩展的。
构建可插件的应用程序
结合依赖倒置原则,我们可以构建出具有高度灵活性和扩展性的可插件应用程序。构建可插件应用程序的核心在于先设计出抽象接口,定义插件如何表达其功能以及如何汇报状态。在接口完成后,开发插件和主程序的工作可以并行进行,主程序只需依赖这个抽象接口来加载和调用插件。
一个典型的例子是游戏中的插件系统。例如,魔兽世界(World of Warcraft)允许玩家通过编写Lua脚本来扩展游戏功能。插件作者只需要遵循游戏提供的API接口,便能实现复杂的功能,如自定义界面、战斗信息统计等。类似地,Minecraft也有一个强大(但每次升级都很费劲)的插件系统,玩家可以通过实现特定的接口来创建新的游戏玩法、物品和机制。
再如,城市规划模拟游戏Cities: Skylines通过Steam创意工坊支持插件,玩家可以创建和分享自定义建筑、交通工具和地形。开发者为插件提供了一套标准接口,确保插件能无缝集成到游戏中。
这种插件化设计不仅适用于游戏,也广泛应用于其他软件系统。例如,许多现代浏览器如Chrome和Firefox通过插件系统让用户扩展浏览器功能。开发者只需按照浏览器提供的API接口编写插件,无需修改浏览器的核心代码。
插件系统的成功关键在于抽象接口的设计。一个好的抽象接口应当具备以下几个特征:
- 简单明了:接口应当尽可能简单,便于理解和实现。
- 高度解耦:接口应当尽量减少对具体实现的依赖,保持模块之间的低耦合。
- 可扩展性:接口设计应考虑未来的扩展需求,允许添加新功能而不破坏现有系统。
举例来说,假设我们正在开发一个图像处理应用,并希望支持各种图像滤镜插件。我们可以先定义一个抽象接口:
public interface ImageFilter {
void applyFilter(Image image);
}
然后,任何实现这个接口的类都可以作为插件加载到应用中。例如,我们可以创建一个灰度滤镜插件:
public class GrayscaleFilter implements ImageFilter {
@Override
public void applyFilter(Image image) {
// 灰度滤镜的实现
}
}
主程序通过反射机制或插件管理器动态加载这些实现了ImageFilter接口的插件,并调用它们的applyFilter方法来处理图像。这样,无论将来需要添加多少种滤镜,只需按照这个接口规范编写插件即可,无需修改主程序代码。
通过这种方式,我们不仅提高了系统的灵活性和可维护性,还为第三方开发者提供了参与和扩展的机会。这正是依赖倒置原则的实际应用,通过依赖于抽象接口而不是具体实现,我们可以构建出更具弹性和扩展性的系统。
理解 ABI
回到我们的主线问题:很多学校的汇编课程都要求学生能够在虚拟机里运行自己的汇编代码。
如果你构建了一个汇编应用,直接在 CPU 上运行,没有操作系统的概念。你的应用本身功能已经不错了,但是你需要允许第三方开发者为你的汇编应用开发插件。这时你会怎么设计?
这时,你需要定义一个接口,来描述它的插件的规范。这个接口的名字叫作 ABI。ABI 是 Application Binary Interface 的缩写。它描述了一个应用程序如何与操作系统或者其他应用程序进行交互。它里面可能定义了一个插件如何启动,如何申请资源,优先级如何,如何释放资源,如何结束。
这个接口就是抽象。它甚至可以先于你的汇编应用本身诞生。
它包括程序的入口点(如Windows的WinMain和Linux的main)、图标和资源文件管理(Windows通过资源文件嵌入,Linux通过.desktop文件定义)、指令集(如x86、x86_64、ARM等)、动态链接库管理(Windows使用DLL,Linux使用.so文件)、调用约定(如Windows的 __stdcall和Linux的cdecl)、以及可执行文件格式(Windows的PE和Linux的ELF)。这些规范确保不同程序在同一系统上兼容运行。
通过定义一个清晰的 ABI,你的汇编应用程序就可以被其他人开发插件了。这个时候,你的汇编应用程序实际上已经变成了一个操作系统。你需要管理插件的加载和卸载,处理插件之间的资源竞争,并确保系统的稳定性和安全性。
这样,你已经理解了操作系统的本质。操作系统就是一个 ABI 的执行者和管理者。它管理着硬件资源的分配,它管理着进程的调度,它管理着文件的读写。
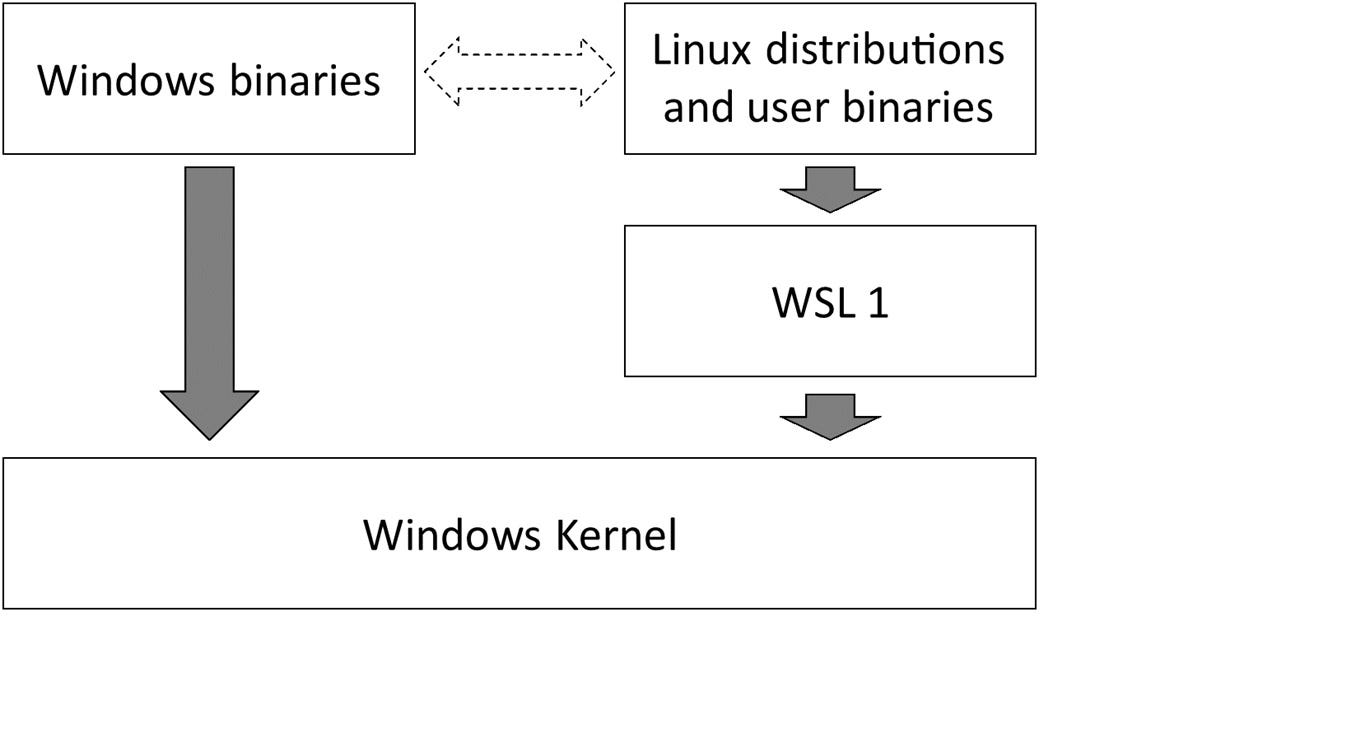
例如,如上图所示,WSL1 实际上实现了 Linux 的 ABI,从而可以在 Windows 的内核上运行 Linux 应用。
ABI 的定义是操作系统和应用程序之间的桥梁。理解了 ABI,你就理解了操作系统的核心功能。它不仅仅是资源管理器,更是一个抽象层,使得应用程序能够在硬件上高效、稳定地运行。这样,操作系统和应用程序的关系也就不再神秘,而是通过 ABI 这个关键点变得清晰明了。
这个问题真的重要吗?
当我们理解了真正的抽象是 ABI(应用二进制接口)以后,操作系统和应用程序谁先诞生的问题还真的重要吗?甚至说,还应该有具体的答案吗?
二者一个是对 ABI 的实现,一个是对 ABI 的使用。ABI 是定义了软件与操作系统之间的接口,它为应用程序提供了一个标准,使得应用程序可以在不同的操作系统上运行,而无需对应用程序本身进行修改。
这个问题的答案其实是:应用程序和操作系统的诞生并不分先后,但是他们都晚于 ABI。在 ABI 出现之前,没有应用程序,也没有操作系统。诞生了 ABI 之后,应用程序和操作系统可以同时诞生。
以鸿蒙操作系统为例,它是兼容 Linux ABI 的,这意味着它可以运行 Linux 的应用程序。Linux 应用无需重新编译,就可以在鸿蒙操作系统上运行。这一事实表明,操作系统和应用程序并不是相互独立的存在,而是通过 ABI 紧密联系在一起的。鸿蒙操作系统的兼容性使得现有的 Linux 应用程序能够在新的操作系统环境中运行。
在这个视角下,操作系统和应用程序谁先诞生的问题变得不再重要。重要的是我们如何定义和实现这些抽象,使得硬件资源能够被高效、安全地利用,使得应用程序能够在不同的环境中运行。
回顾本科
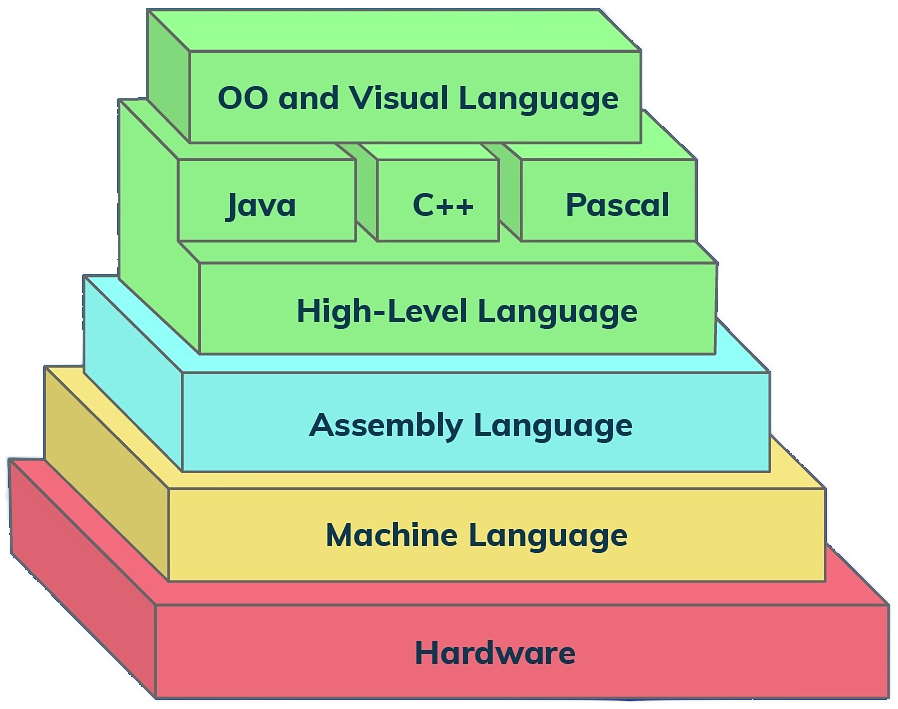
如上图所示。对于没有了解过 ABI 和汇编的人,他们只能理解到高级语言。而操作系统、硬件和语言的行为对他们来说就是一种魔法。
我非常庆幸我本科选择修了汇编。虽然具体的语法我也忘得一窍不通了,但今天学习汇编不仅仅是为了编写低级代码,更是为了理解计算机的运行机制。汇编语言让我们看到了程序是如何被加载到内存中,如何通过指令被CPU执行,如何进行内存管理和资源分配。以面向对象编程为例,虚函数的实现实际上依赖于函数指针表,而这些细节在高级语言中被隐藏,但在汇编中却暴露无遗。通过汇编,我们理解了函数指针的概念,看到了内存地址是如何被管理和使用的,这为我们理解面向对象编程和多态性奠定了基础。
操作系统课程中涉及的死锁检测、内存分页、进程调度等内容,都是计算机科学的核心。没有对这些概念的深入理解,就无法真正掌握系统的底层运行机制。比如,死锁问题虽然在高层应用中不常见,但在操作系统和数据库系统中却是一个必须解决的问题。理解内存分页和进程调度的原理,有助于我们优化程序性能,设计高效的算法,提升系统的稳定性和响应速度。
在数据中心管理和网络安全领域,对操作系统的深刻理解同样至关重要。知道操作系统如何管理资源、如何进行权限控制、如何处理异常情况,才能设计出安全可靠的系统,防范潜在的攻击。编译器开发和嵌入式系统的设计更是如此,只有理解了底层硬件和操作系统的运行机制,才能编写出高效、稳定的代码。
总的来说,本科期间学习汇编和操作系统,不仅是为了掌握编程技巧,更是为了理解计算机科学的基础原理。这些知识不仅仅是为了应对考试或完成作业,而是为了在未来的职业生涯中,能够应对各种复杂的问题,设计出高效、安全、稳定的系统。这种基础知识的欠缺,会导致我们在面对复杂系统时束手无策,使计算机成为一个难以理解的黑盒。因此,无论未来的技术如何发展,这些基础知识都是不可或缺的。
回复
应用软件只是服务于操作系统之上运行的,依赖操作系统提供的功能和服务!
在计算机科学的教育和实验中,学生和研究人员经常从零开始编写简单的操作系统和应用程序。例如许多大学的操作系统课程要求学生编写一个简单的操作系统,然后在其上运行自制的应用程序。最初的应用程序可能是非常基本的,比如打印“Hello, World!”的程序。这些实验展示了应用程序可以在操作系统完成之前就存在并运行。例如:一些高性能计算应用和实时系统直接在硬件上运行,不使用操作系统。开发者编写直接与硬件交互的代码,以实现极高的性能或实时性。
在计算机启动时,最先运行的是引导加载程序(如BIOS或UEFI),它加载并执行操作系统内核。在某些情况下,引导加载程序本身就可以运行简单的应用程序。
虽然现代大多数应用程序确实运行在操作系统之上,并依赖操作系统提供的功能和服务,但这并不意味着应用程序必须在操作系统之后诞生。二者并无逻辑联系。二者都依赖的是抽象。早期计算机、嵌入式系统、自制操作系统以及现代的裸机编程等例子都表明,应用程序可以独立于操作系统存在和运行。因此,应用软件并不一定必须依赖操作系统,应用程序和操作系统的关系更加复杂和多样化。
文章通过ABI这一抽象层重新定义了操作系统与应用程序的关系,这种视角颇具启发性。但若进一步探讨,现代软件生态中抽象的边界是否已悄然变化?以WebAssembly为例,它正在成为一种新的"虚拟ABI",允许不同语言编译的程序在浏览器沙箱中运行,这是否意味着传统的ABI概念正在被更动态的抽象层所替代?当云原生应用通过Kubernetes调度时,底层硬件架构的差异被层层封装,此时应用程序对"操作系统"的依赖是否也呈现出新的形态?或许未来的讨论焦点,将从ABI的静态规范转向运行时环境的动态适配能力。
这篇文章从多个角度探讨了计算机科学教育中的一些核心问题,尤其是操作系统、应用程序与硬件之间的关系,以及学习汇编语言的重要性。作者通过回顾本科课程内容,强调了理解底层机制对高级编程和系统设计的深远影响。
文中提到的“应用程序和操作系统的诞生并不分先后”这一观点非常值得深思。在现代计算中,虽然大多数应用场景都依赖于操作系统提供的抽象层,但在某些特定领域(如嵌入式系统或裸机编程),应用程序确实可以直接与硬件交互。这种灵活性不仅是技术发展的体现,也说明计算机科学的复杂性远超表面认知。
此外,文章提到的“函数指针表”和内存管理机制如何通过汇编语言暴露出来,让我联想到面向对象编程中的多态性实现原理。这些底层细节虽然在高级语言中被封装,但了解它们的本质有助于开发者更好地理解程序运行时的行为,从而写出更高效、更安全的代码。
最后,作者提到的“计算机科学的基础知识”确实是技术发展的基石。无论是优化系统性能还是设计复杂的应用架构,这些基础知识都是不可或缺的能力储备。这让我想到一个比喻:高级编程语言是工具,而底层机制是工具背后的原理。只有理解了工具的工作方式,才能真正成为工具的主人。
总的来说,这篇文章不仅是一次对计算机科学教育的反思,也提醒我们,无论技术如何发展,理解底层机制和抽象原理始终是提升自身能力的关键路径。
非常感谢你的博客,我对你对依赖倒置原则的解释和应用印象深刻。你清楚地解释了为什么我们应该依赖于抽象而不是具体实现,并通过一个简单的示例代码展示了如何使用接口来实现依赖倒置。这种设计方法确实能够使系统更加灵活和可扩展。
我也很喜欢你关于构建可插件应用程序的部分。你的解释很清晰,说明了如何使用依赖倒置原则和抽象接口来构建具有高度灵活性和扩展性的应用程序。你的例子包括游戏插件系统、浏览器插件系统以及城市规划模拟游戏的插件系统,这些都很好地展示了插件化设计的优势和实际应用。
此外,你对 ABI 的解释也很有启发性。你清楚地解释了 ABI 在应用程序和操作系统之间的作用,以及 ABI 的定义和设计原则。你的例子包括 Windows API 和 Linux ABI,这些都很好地说明了 ABI 在操作系统和应用程序之间的关键作用。
然而,我认为有一些地方可以进一步改进。在你对操作系统和应用程序哪个先诞生的问题的回答中,我认为你的观点有些片面。虽然你指出了 ABI 的重要性,但你没有提到操作系统和应用程序的发展是相互促进的。实际上,操作系统的发展推动了应用程序的创新,而应用程序的需求也推动了操作系统的演进。这种相互作用是计算机科学发展的重要推动力。
另外,在你对本科学习汇编和操作系统的回顾中,我认为你可以更加具体地说明汇编和操作系统对于理解计算机运行机制的重要性。你提到了一些例子,但没有展开讨论它们是如何帮助你理解计算机科学的基础原理的。如果你能提供更多的实际例子和经验,读者可能会更好地理解汇编和操作系统的重要性。
总的来说,你的博客内容很有深度和广度,对于理解依赖倒置原则、构建可插件应用程序以及理解操作系统和应用程序之间的关系都非常有帮助。如果你能进一步改进你的回答,提供更多实际例子和经验,我相信读者会更好地理解和欣赏你的博客。再次感谢你的分享!