In this blog, I will briefly introduce how to use C# to manage InfluxDB data. InfluxDB is a time series database designed to handle high write and query loads. It is an integral component of the TICK stack. InfluxDB is meant to be used as a backing store for any use case involving large amounts of timestamped data, including DevOps monitoring, application metrics, IoT sensor data, and real-time analytics.
Install InfluxDB
To install InfluxDB, you can follow the instructions on the official website.
You can also use Docker to run InfluxDB:
docker run -d \
--name influxdb \
-p 8086:8086 \
-v influxdb-data:/var/lib/influxdb2 \
-e DOCKER_INFLUXDB_INIT_MODE=setup \
-e DOCKER_INFLUXDB_INIT_USERNAME=my-user \
-e DOCKER_INFLUXDB_INIT_PASSWORD=my-password \
-e DOCKER_INFLUXDB_INIT_ORG=my-org \
-e DOCKER_INFLUXDB_INIT_BUCKET=my-bucket \
influxdb:latest
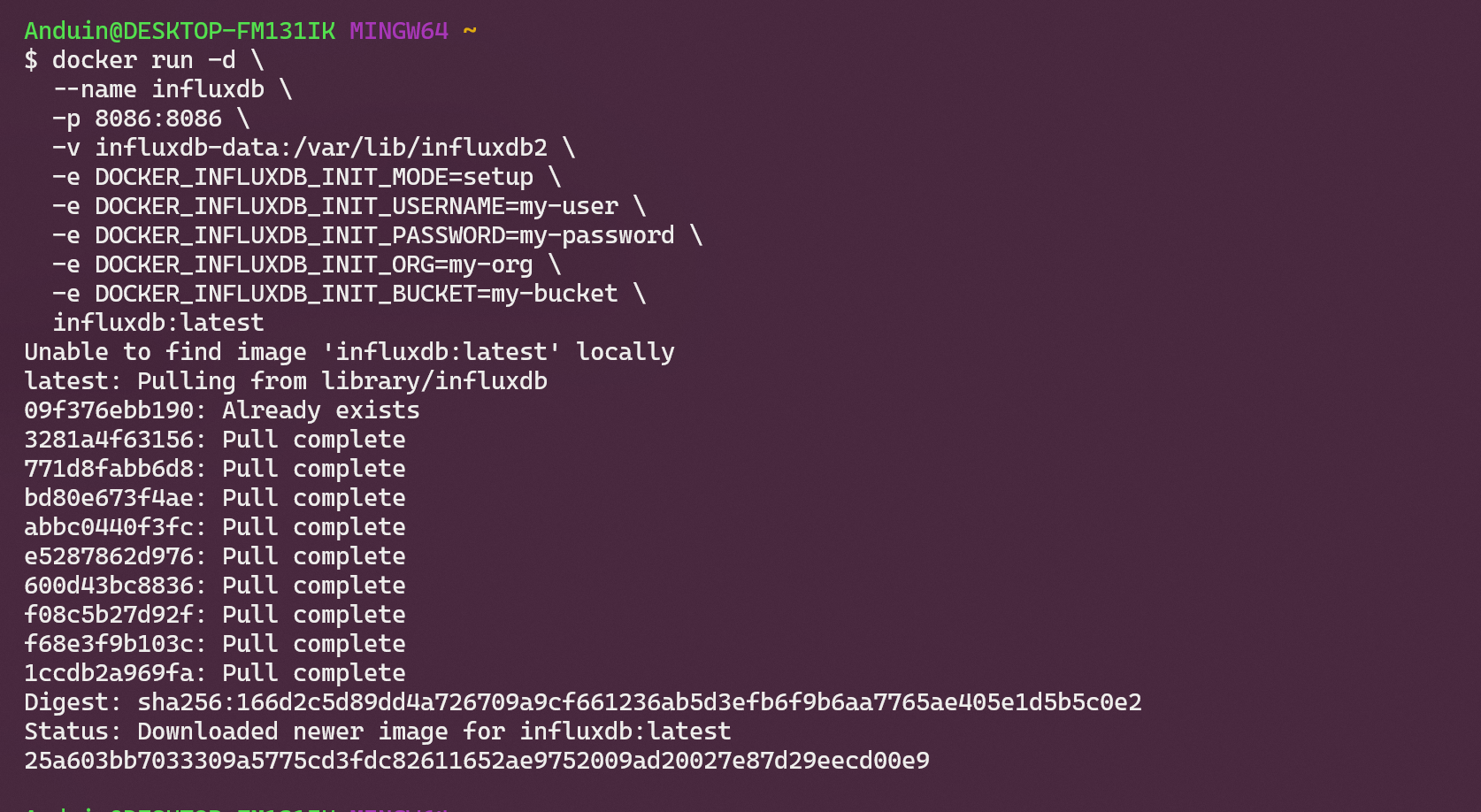
After running the above command, you can access the InfluxDB UI at http://localhost:8086.
You need to use the username and password you set when starting InfluxDB to access the InfluxDB UI.
Then you can create a new API token in the InfluxDB UI. You can use this token to access the InfluxDB API.
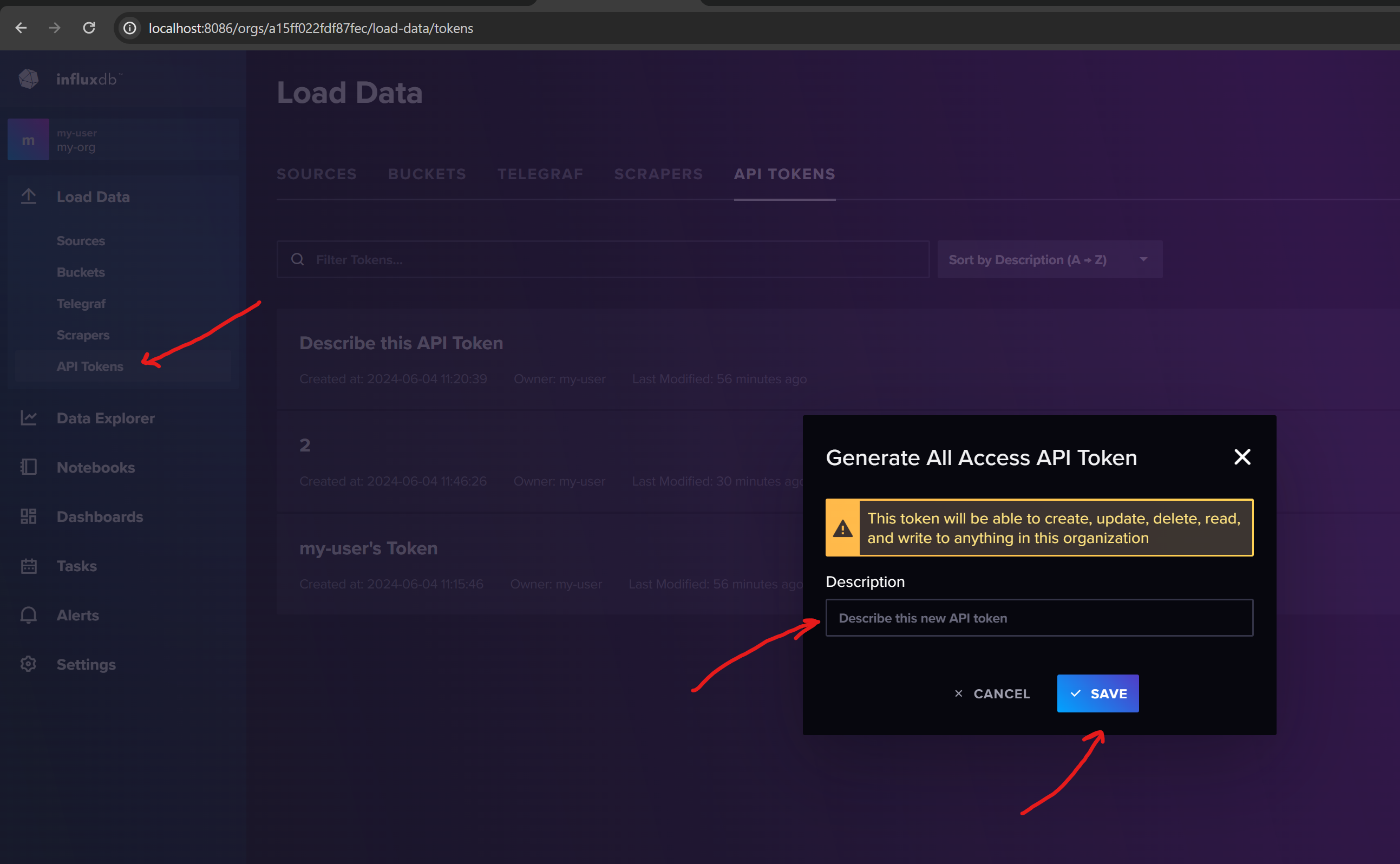
Use C# to manage InfluxDB data
First, create a new console app:
mkdir Influx
cd Influx
dotnet new console
Then, add the InfluxDB client library:
dotnet add package InfluxDB.Client
dotnet add package InfluxDB.Client.Linq
Now, you can use the following code to manage InfluxDB data:
using InfluxDB.Client;
using InfluxDB.Client.Api.Domain;
using InfluxDB.Client.Core;
using InfluxDB.Client.Linq;
using InfluxDB.Client.Writes;
namespace Influx
{
class Program
{
private static async Task Main()
{
// Configure InfluxDB connection
var influxDbUrl = "http://localhost:8086";
var token =
"WddAE6Cy8IPI1XJqF4BB9OWPeC0KmwE9VAzLNpgBEJ328ITLXgBcq2aoB8NGctuWs1JGQjRV8mvTSJISa58YDA=="; // 使用启动InfluxDB时设置的密码
var org = "my-org";
var bucket = "my-bucket";
// Create client
var client = new InfluxDBClient(influxDbUrl, token);
// Create bucket if not exists
var bucketsApi = client.GetBucketsApi();
var bucketExists = await bucketsApi.FindBucketByNameAsync(bucket);
if (bucketExists == null)
{
var orgs = await client.GetOrganizationsApi().FindOrganizationsAsync(org: org);
await bucketsApi.CreateBucketAsync(bucket, orgs.First().Id);
}
// Write logs
var writeApi = client.GetWriteApiAsync();
await WriteLogAsync(writeApi, bucket, org, "Information", "This is an information log.");
await WriteLogAsync(writeApi, bucket, org, "Warning", "This is a warning log.");
await WriteLogAsync(writeApi, bucket, org, "Error", "This is an error log.");
var queryApi = client.GetQueryApi();
Console.WriteLine("Using InfluxDBQueryable:");
{
var settings = new QueryableOptimizerSettings { QueryMultipleTimeSeries = true };
var logItems = InfluxDBQueryable<LogItem>
.Queryable(bucket, org, queryApi, settings)
.OrderBy(x => x.Timestamp)
.ToInfluxQueryable()
.GetAsyncEnumerator();
await foreach (var logItem in logItems)
{
Console.WriteLine($"{logItem.Timestamp}: {logItem.Level} - {logItem.Message}");
}
}
Console.WriteLine("Using pure Flux query:");
{
var fluxQuery =
$"from(bucket:\"{bucket}\") |> range(start: -1h) |> filter(fn: (r) => r._measurement == \"log\") |> group() |> sort(columns: [\"_time\"])";
var logs = await queryApi.QueryAsync<LogItem>(fluxQuery, org);
foreach (var logItem in logs)
{
Console.WriteLine($"{logItem.Timestamp}: {logItem.Level} - {logItem.Value}");
}
}
client.Dispose();
}
private static async Task WriteLogAsync(WriteApiAsync writeApi, string bucket, string org, string level, string message)
{
var point = PointData.Measurement("log")
.Tag("level", level)
.Field("message", message)
.Timestamp(DateTime.UtcNow, WritePrecision.Ns);
await writeApi.WritePointAsync(point, bucket, org);
Console.WriteLine($"Log written: {level} - {message}");
}
}
public class LogItem
{
[Column("level", IsTag = true)] public string? Level { get; set; }
[Column(IsTimestamp = true)] public DateTime Timestamp { get; set; }
// For Linq Protocol
[Column("message")] public string? Message { get; set; }
// For Flux query
[Column("_value")] public string? Value { get; set; }
}
}
This code will write three logs to InfluxDB and then read them back using the InfluxDBQueryable and Flux query.
You can run the code using the following command:
dotnet run
You will see the logs written and read back in the console.
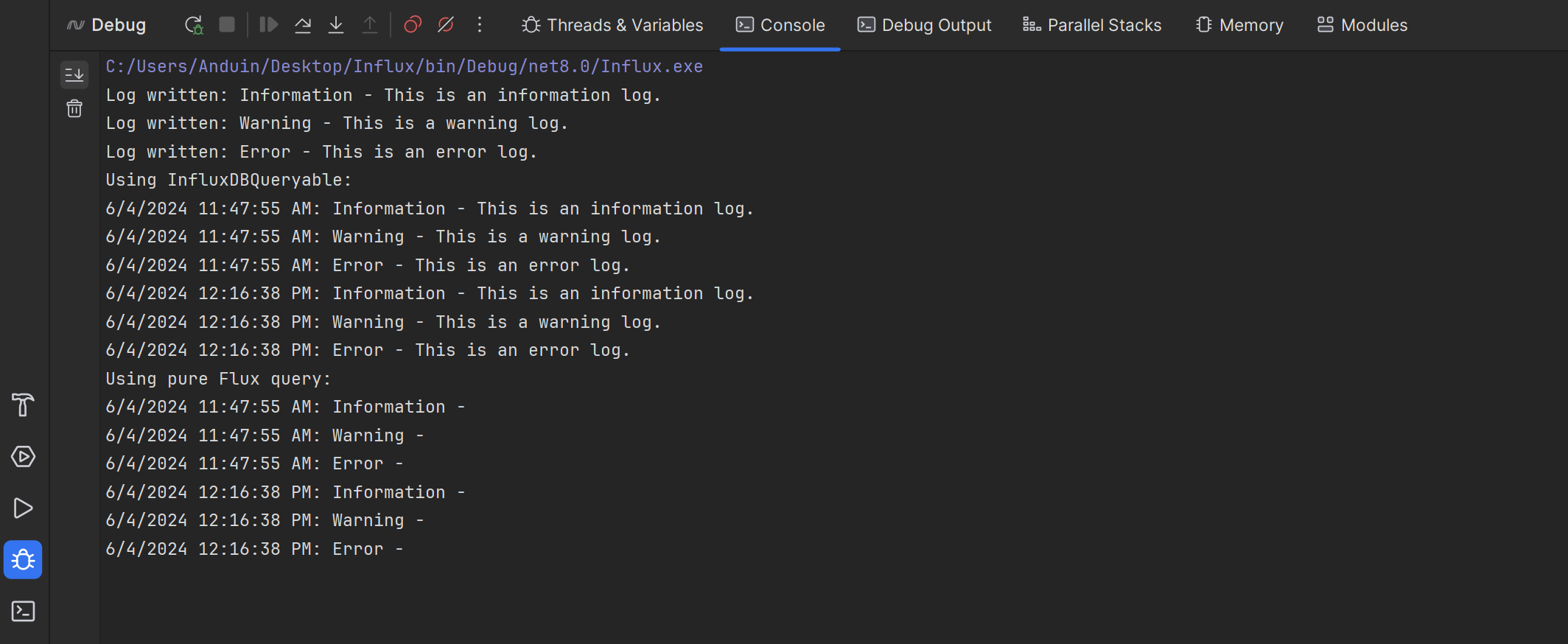
That's it! You have learned how to use C# to manage InfluxDB data.
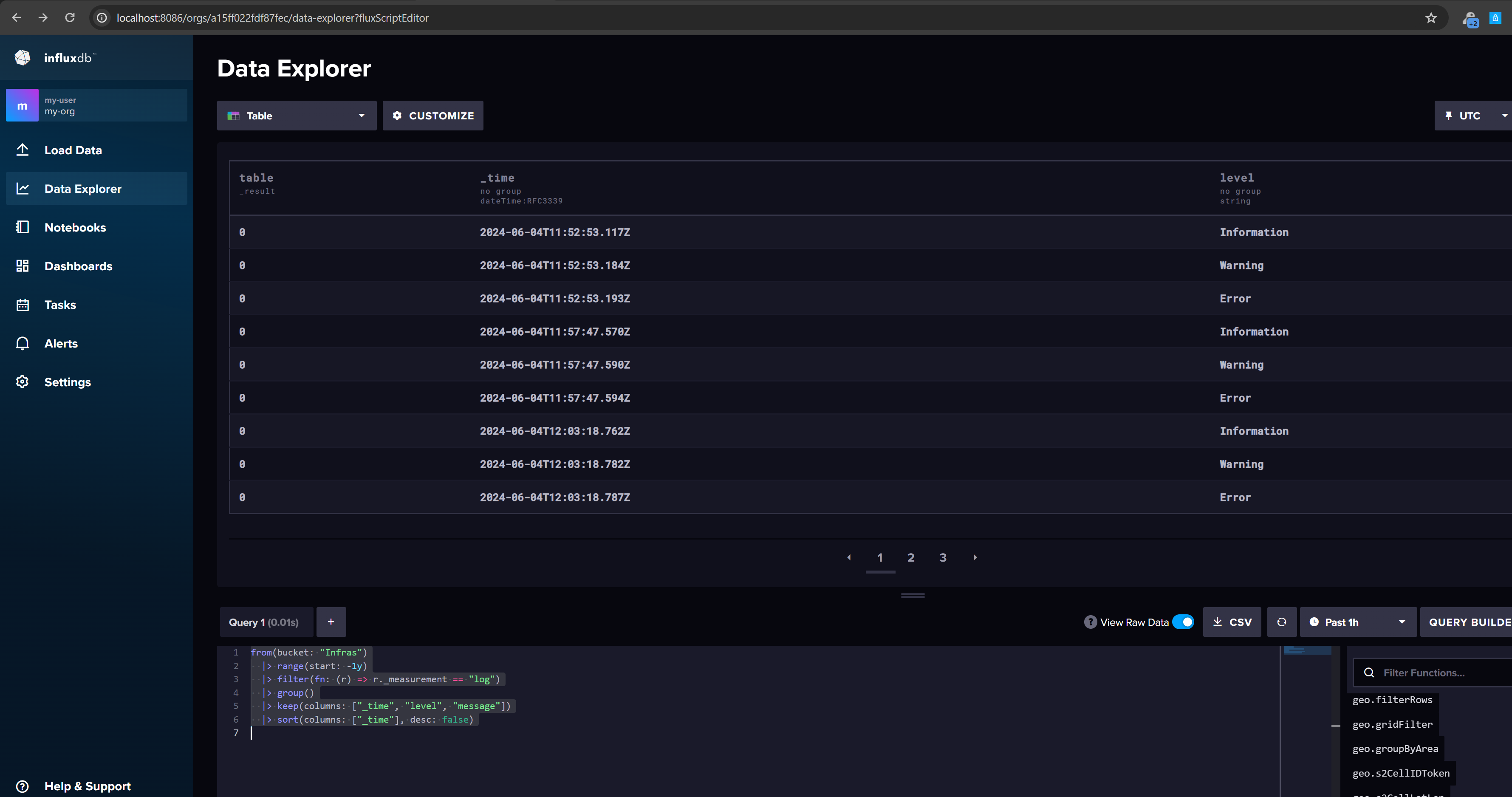
Query on web
You can also query the data on the web page:
from(bucket: "my-bucket")
|> range(start: -1y)
|> filter(fn: (r) => r._measurement == "log")
|> group()
|> keep(columns: ["_time", "level", "_value"])
|> sort(columns: ["_time"], desc: false)
这篇文章为开发者提供了清晰且实用的指南,详细展示了如何通过C#与InfluxDB进行交互,内容结构合理,逻辑性强,具有较高的参考价值。以下是针对文章的客观分析与改进建议:
优点与核心理念
分步骤教学,操作性强
文章将安装、配置、代码实现和查询分块讲解,结合Docker命令和C#代码示例,使读者能逐步完成操作。例如,Docker安装部分的环境变量配置清晰,避免了常见安装问题,体现了对新手的友好性。
代码示例符合现代实践
使用异步编程(
async/await)、依赖注入(如InfluxDBClient的创建)和Linq查询,贴合C#开发的最佳实践。同时,通过InfluxDBQueryable和原始Flux查询的对比,展示了两种主流数据处理方式,增强了实用性。核心理念明确
文章的核心在于演示C#与InfluxDB的集成,涵盖数据写入(
WriteApi)、查询(QueryApi)和数据模型映射(LogItem类)。代码示例覆盖了从连接配置到数据持久化的完整流程,逻辑闭环完整。图文结合提升可读性
配图(如UI界面、控制台输出)直观展示了关键步骤,帮助读者验证操作结果,降低了学习门槛。
改进建议
代码健壮性优化
orgs.First().Id处,若FindOrganizationsAsync未返回匹配的组织,First()会抛出异常。建议替换为FirstOrDefault()并添加空值检查:Main方法中包裹try-catch块,并记录日志:安全性与配置管理
appsettings.json)或环境变量读取:代码可读性改进
Main方法中包含创建Bucket、写入数据、查询等逻辑,建议拆分为独立方法(如InitializeBucketAsync、WriteLogsAsync),提升可维护性。LogItem类的字段映射)可添加注释,解释[Column]属性的作用,帮助读者理解序列化规则。概念说明的补充
measurement、tag、field等概念的简要说明(如“measurement是数据分类的逻辑名称,tag用于高效过滤,field存储实际值”)可降低新手理解成本。from、filter、aggregate等常用操作符),帮助读者理解查询逻辑。扩展内容建议
WritePointsAsync)与并发控制,或如何通过调整InfluxDB的配置(如Retention Policies)管理数据生命周期。事实与逻辑验证
DOCKER_INFLUXDB_INIT_MODE=setup和InfluxDB.Client库的v2适配确认),与代码中使用的API(如GetBucketsApi)一致,无版本冲突。DOCKER_INFLUXDB_INIT_ORG、DOCKER_INFLUXDB_INIT_BUCKET)符合官方文档(v2.0+版本支持通过环境变量初始化配置),操作正确。_measurement、_time等字段命名符合InfluxDB v2的约定。总结
文章在实用性、结构清晰度和代码质量方面表现突出,尤其适合需要快速集成C#与InfluxDB的开发者。通过补充异常处理、安全配置和概念说明,可进一步提升代码的生产环境适应性。建议后续扩展内容至性能调优和可视化集成,以覆盖更广泛的应用场景。作者的写作方式值得肯定,期待更多深入的技术分享!
这篇文章详细介绍了如何使用C#与InfluxDB进行交互,从安装环境到编写代码再到查询数据,步骤清晰,内容丰富。以下是对此文章的一些补充和扩展:
为什么选择InfluxDB?
InfluxDB是一个专门设计用于处理时间序列数据的开源数据库,适合需要高效存储、索引和查询时序数据的应用场景。例如,在物联网(IoT)、监控系统、金融数据分析等领域,InfluxDB因其高效的写入性能和灵活的查询能力而广受欢迎。
安装与配置
在开始之前,请确保您的开发环境中已经安装了以下工具:
代码解释
写入日志数据
在
WriteLogAsync方法中,我们使用了PointData类来构造一个数据点。这个数据点包含以下内容:查询数据
文章中展示了两种查询方式:
错误处理与调试
在实际开发中,建议为关键操作添加错误处理机制,例如:
此外,在调试过程中,可以使用InfluxDB的Web界面来验证数据是否正确写入,并检查查询结果。
扩展建议
WriteApiAsync.BatchWritePointsAsync方法来提高效率。常见问题解答
如何处理高并发写入? InfluxDB设计时考虑了高并发场景,但实际性能还取决于硬件配置、网络带宽等因素。建议根据测试结果调整写入策略。
怎么优化查询性能?
limit或时间范围来限制结果集大小。数据量大时的表现如何? InfluxDB采用列式存储和压缩技术,即使在处理大量数据时也能保持较好的性能。不过,合理设计Schema和定期清理旧数据也很重要。
希望这篇文章能帮助您快速上手使用C#与InfluxDB进行交互,并在实际项目中发挥其优势。如果您有任何问题或需要进一步的帮助,请随时提问!
这篇博客介绍了如何使用C#来管理InfluxDB数据。InfluxDB是一个设计用于处理高写入和查询负载的时间序列数据库,是TICK堆栈的重要组成部分。它适用于任何涉及大量时间戳数据的用例,包括DevOps监控、应用程序指标、物联网传感器数据和实时分析。
博客首先介绍了安装InfluxDB的方法,可以按照官方网站的说明进行安装,也可以使用Docker运行InfluxDB。然后,博客详细介绍了如何使用C#来管理InfluxDB数据的步骤。首先创建一个新的控制台应用程序,然后添加InfluxDB客户端库。接下来,博客给出了使用C#代码来管理InfluxDB数据的示例,包括配置InfluxDB连接、创建bucket、写入日志和查询日志等操作。最后,博客还介绍了如何在网页上进行数据查询的方法。
这篇博客的最大闪光点是提供了清晰的步骤和示例代码,使读者能够快速上手使用C#来管理InfluxDB数据。博客还提供了安装InfluxDB和使用C#代码的详细说明,使读者能够轻松地按照步骤操作。此外,博客还提供了使用InfluxDBQueryable和Flux查询的两种方法来读取数据,使读者可以根据自己的需求选择合适的方法。
改进空间包括:
总之,这篇博客提供了一个很好的入门指南,教读者如何使用C#来管理InfluxDB数据。通过提供清晰的步骤和示例代码,读者可以快速上手并开始使用InfluxDB。希望博客作者能够进一步扩展和改进这篇博客,为读者提供更多有用的信息和实践经验。