在 2023年 9月1日 UTC时间的 10:01 分,Aiursoft 发生了一次重大事故。
所有服务全部中断,并且损失了一些数据。当天可用性严重降级。
我们花费了大约4个小时,尝试理清这一切发生了什么。下面是详细过程。
背景
Aiursoft 的基础设施运行在一个Vsphere 数据中心中,使用了存储计算分离的设计,由多台 ESXI 进行计算,由一台 NFS 服务器进行存储。
这台 NFS 服务器具有 12 块东芝的 2T 低价机械硬盘,有两块 6TB 戴尔企业级 NVME 固态硬盘。
之前,这个 NFS 服务器的配置方法是:将12块 2T 机械组成 ZFS Pool,并使用那两块企业级固态作为 ZFS 的缓存,从而同时享受机械的容量和固态的性能。

但是,很快我们发现,这样搭配的结果,性能比纯固态还是要差一些。
变更
于是,我们考虑到 ZFS 机械硬盘+固态缓存的性能会形成瓶颈😐,因此就决定放弃使用机械硬盘来提供业务,转而将机械硬盘用于纯备份,而将全部数据放在NVME固态中。
经过测试,上述改造可以有效提高所有业务的读写速度,尤其是随机读写速度。
因此在 2023 年 8 月 30 日,我们放弃了使用固态硬盘作为缓存的思路,而是将两块 NVME 固态组合成了一个 RAID 0 的ZFS Pool,并创建了dataset:NVME,挂载到了 /mnt/nvme ,以提供 NFS 存储服务。
很快我们就开始享受纯NVME的性能增益了。确实纯 NVME 固态对性能提升非常明显。尤其是开机、更新、安装系统的速度都显著增益。
当然,此时此刻我们还没有配好备份。因此这是非常危险的一个阶段:全部用户数据都被放在了 RAID 0 中!一旦任意一块硬盘损坏,都会损失所有数据,而且无法恢复。
危机
当然我们理解这个阶段的危险性。因此,立刻对 NVME 固态的数据设计备份是一个非常要紧的工作。
我们最开始尝试了 rsync 备份,但是考虑到要备份的文件都在被高速读写,使用 rsync 的效率很低,甚至很难完整复制完一个正在被读写的文件。
sudo rsync -avh --inplace --partial --delete --progress /mnt/nvme/ /mnt/pool/backup/
既然使用了ZFS,我们决定使用 ZFS 的快照功能来备份。ZFS的快照功能非常强大,可以在不停止服务的情况下,对文件系统进行快照,然后将快照发送到其他地方。
因此,我们开发了这样一段备份脚本:
#sudo rsync -avh --inplace --partial --delete --progress /mnt/nvme/ /mnt/pool/backup/
echo "Installing prerequisites..."
sudo apt install -y pv
echo "Deleting existing backups..."
sudo zfs destroy pool/backup@backup
sudo zfs destroy nvme/data@backup
echo "Creating snapshot..."
sudo zfs snapshot -r nvme/data@backup
echo "Sending snapshot from nvme/data to pool/backup..."
sudo zfs send -vR nvme/data@backup | pv | sudo zfs receive -vF pool/backup
echo "Deleting data backup"
sudo zfs destroy nvme/data@backup
上述脚本的作用是对 /mnt/nvme/data 进行快照,然后将快照发送到 /mnt/pool/backup 中。
理论上它非常安全,因为它不会修改生产环境的数据,并且会在发送完毕后删除在NVME上的快照以释放空间。发送快照的目标是一个独立的ZFS Pool,因此即使发送失败,也不会影响生产环境。
考虑到它的安全性,这段脚本在开发完成后,我们没有在任何试验环境中测试,而是直接在生产环境中运行。当然,实践证明这个决定是非常错误的。
事故
在 2023 年 9 月 1 日,我们在 10:01 UTC 时间收到了一条警报,说业务已经停止。
我此时此刻正在 NFS 上检查性能信息,因此我正好开始了调查。
出于对 Vsphere 数据中心的调查流程,我立刻检查了 Vsphere 的状态,此时发现所有 VM 已经全部停止,并且都发生了错误,处于 Orphan 状态。
我试图通过 VCenter 重启所有 VM,但是发现所有 VM 都无法启动,因为它们的磁盘都无法找到。
我试图在 ESXI 上访问 NFS,发现 NFS 无法访问。此时可以判断:NFS 服务器已经停止。
于是我立刻登录 NFS,并且在 NFS 上运行了下列命令:
(这部分是在事故发生后真实运行的源命令归档)
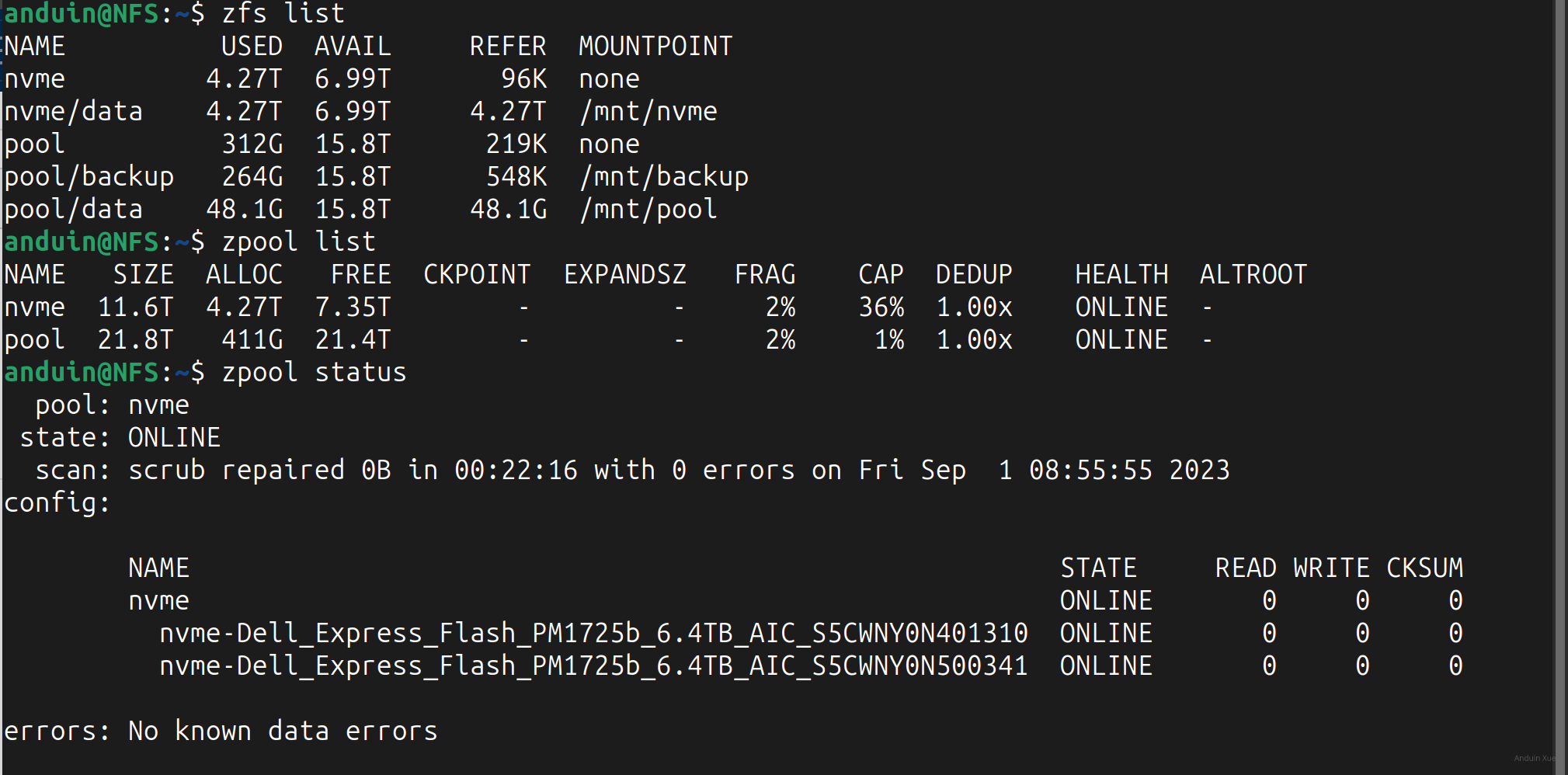
anduin@NFS:~$ zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
nvme 11.6T 4.28T 7.35T - - 3% 36% 1.00x ONLINE -
pool 21.8T 5.02T 16.8T - - 2% 23% 1.00x ONLINE -
anduin@NFS:~$ zpool status
pool: nvme
state: ONLINE
scan: scrub repaired 0B in 00:22:16 with 0 errors on Fri Sep 1 08:55:55 2023
config:
NAME STATE READ WRITE CKSUM
nvme ONLINE 0 0 0
nvme-Dell_Express_Flash_PM1725b_6.4TB_AIC_S5C112 ONLINE 0 0 0
nvme-Dell_Express_Flash_PM1725b_6.4TB_AIC_S5C111 ONLINE 0 0 0
errors: No known data errors
pool: pool
state: ONLINE
scan: scrub in progress since Fri Sep 1 08:35:37 2023
3.41T scanned at 1.22G/s, 110G issued at 39.4M/s, 4.05T total
0B repaired, 2.66% done, 1 days 05:09:52 to go
config:
NAME STATE READ WRITE CKSUM
pool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-TOSHIBA_HDWD120_33GU8WUAS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_33GV7R9AS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_33GVJ01GS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_33UW1T0AS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_52QPEN1AS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_52VPEEUAS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_62BPNH6AS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_62DPLXKAS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_62DPLY6AS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_62DPS2ZAS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_821NVTHAS ONLINE 0 0 0
ata-TOSHIBA_HDWD120_821P90RAS ONLINE 0 0 0
errors: No known data errors
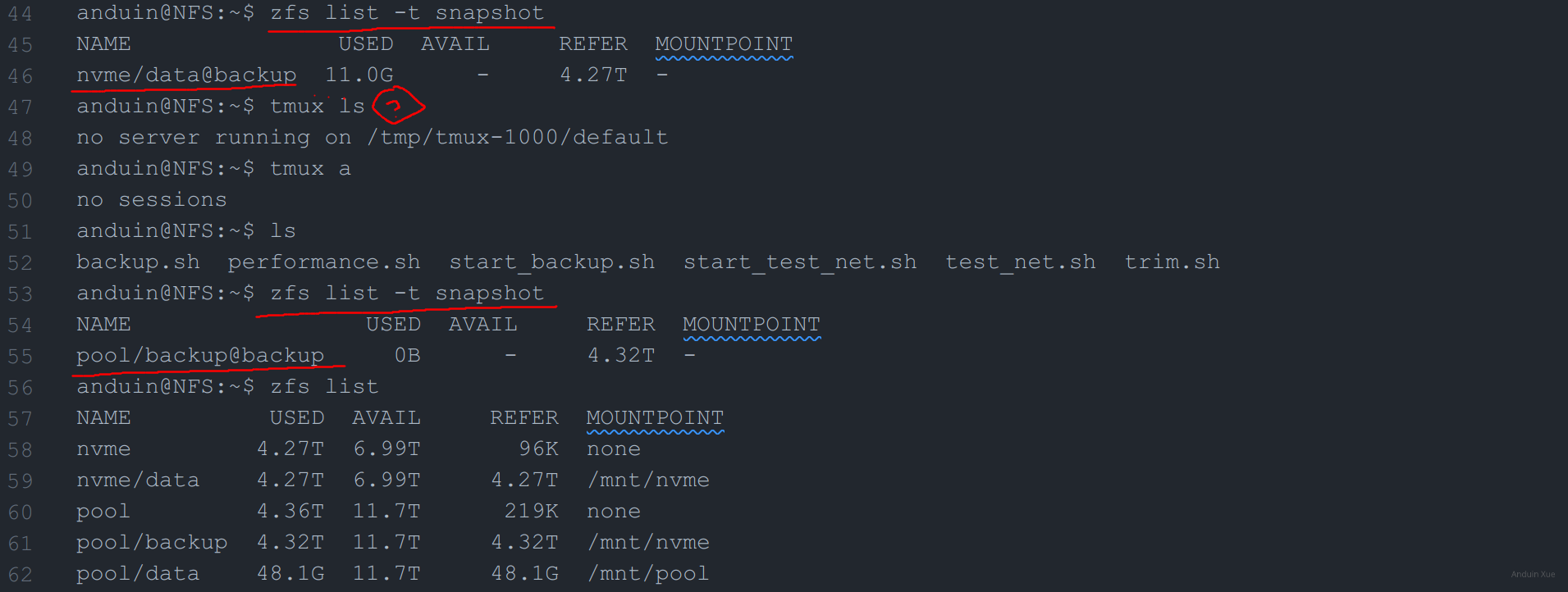
anduin@NFS:~$ zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
nvme/data@backup 11.0G - 4.27T -
anduin@NFS:~$ tmux ls
no server running on /tmp/tmux-1000/default
anduin@NFS:~$ tmux a
no sessions
anduin@NFS:~$ zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
pool/backup@backup 0B - 4.32T -
上面的信息显示,NFS 服务器的两块 NVME 固态都在线,机械硬盘也在线。我的备份脚本是使用 tmux 来运行的,因此我尝试使用 tmux ls 来查看 tmux 的状态,但是发现 tmux 服务已经停止。
但是诡异的事情是:两次我运行 zfs list -t snapshot 的结果竟然是不一样的!第一次运行时,显示了一个名为 nvme/data@backup 的快照,但是第二次运行时,快照就消失了!并且出现了:pool/backup@backup快照。
这个时候我认为我应该立刻去检查数据还在不在。因为现在是特殊情况:我的数据只有一份,并且使用了 RAID 0,一旦发生数据丢失后果将是灾难性的。
于是我立刻尝试访问 NFS 上的数据:
anduin@NFS:~$ cd /mnt/backup/
anduin@NFS:/mnt/backup$ ls
anduin@NFS:/mnt/backup$ cd /mnt/nvme/
anduin@NFS:/mnt/nvme$ cd /mnt/nvme/
anduin@NFS:/mnt/nvme$ ls
Aiursoft Books Dvorak Gbiner GPT Jimmoen Live Monitoring NugetNinja Rdf Runner1 Shubuzuo
幸运的是:数据还在。
此时我也注意:虽然 /mnt/nvme 也就是生产的 NFS 路径有数据,但是 /mnt/backup 是没有数据的。不过并不奇怪这件事,因为备份脚本的作用只是发送一个快照,而不是将数据复制到另一个地方。
既然数据还在,为什么 NFS 服务器会停止呢?
于是我试着探究更多线索:
anduin@NFS:~$ zfs list
NAME USED AVAIL REFER MOUNTPOINT
nvme 4.27T 6.99T 96K none
nvme/data 4.27T 6.99T 4.27T /mnt/nvme
pool 4.36T 11.7T 219K none
pool/backup 4.32T 11.7T 4.32T /mnt/nvme
pool/data 48.1G 11.7T 48.1G /mnt/pool
在上面的输出中,我惊讶的发现,有两个 zfs dataset 的 MOUNTPOINT 竟然是同一个目录!这是不可能的,因为 ZFS 不允许两个 dataset 挂载到同一个目录。
这种情况已经远远超过了我的理解范围,因此我尝试将两个 dataset 的 MOUNTPOINT 改为不同的目录:
anduin@NFS:/mnt/nvme$ sudo zfs set mountpoint=/mnt/backup pool/backup
cannot unmount '/mnt/nvme': unmount failed
anduin@NFS:/mnt/nvme$ sudo zfs set mountpoint=/mnt/backup pool/backup
cannot unmount '/mnt/nvme': unmount failed
在这里我浪费了非常长的时间,尝试将两个 dataset 的 MOUNTPOINT 改为不同的目录,但是都失败了。它的错误信息是:无法卸载 /mnt/nvme,因为它是一个忙碌的目录。我认为这个错误是合理的,因为 /mnt/nvme 是 NFS 的挂载点,NFS 是不会自动卸载的。
于是我尝试了重启 NFS 服务:
anduin@NFS:/mnt/nvme$ sudo systemctl stop nfs-kernel-server
然后尝试了再次修改 MOUNTPOINT:
anduin@NFS:/mnt$ sudo zfs set mountpoint=/mnt/backup pool/backup
anduin@NFS:/mnt$ zfs list
NAME USED AVAIL REFER MOUNTPOINT
nvme 4.27T 6.99T 96K none
nvme/data 4.27T 6.99T 4.27T /mnt/nvme
pool 4.36T 11.7T 219K none
pool/backup 4.32T 11.7T 4.32T /mnt/backup
pool/data 48.1G 11.7T 48.1G /mnt/pool
于是我重启了 NFS 服务:
anduin@NFS:/mnt$ sudo systemctl start nfs-kernel-server
然后我尝试访问 NFS 服务器时,问题已经得到了解决。
实际我恢复 Vsphere 数据中心花了非常久,这是由于 Orphan 状态的 VM 无法通过 VCenter 进行管理,因此我需要手动在 ESXI 上进行管理。而且由于 NFS 服务器的数据已经损坏,因此我需要手动删除所有 VM ,然后重新挂载。
另外,由于数据中心开启了 DPM 和 DRS,以及开启了使用 NFS 的 HA,在事故发生时,HA 系统已经认为系统已经损坏,因此不停尝试将 VM 迁移,而 DPM 甚至为了省电对 ESXI 进行了关机。这些都导致了我在恢复数据中心时遇到了非常多的问题。
后面的修复工作大约花费了 3 个小时,最终在 13:00 UTC 时间,我们的数据中心恢复了正常。
原因
虽然我们的数据中心已经恢复了正常,但是仍然需要弄清楚这一切发生了什么。
尤其是最诡异的现象,为什么两次列举快照出现了不同的结果?为什么两个 dataset 的 MOUNTPOINT 竟然是同一个目录?
第一个问题,在仔细阅读备份脚本后有了解答:
备份脚本会在 nvme 上创建一个快照,随后将快照复制到另一个pool,然后删除快照。此时 tmux 显示备份已经结束,因此很可能在第一次运行 zfs list -t snapshot 时,脚本的运行还没结束,而是在 sudo zfs send -vR nvme/data@backup | pv | sudo zfs receive -vF pool/backup。
#sudo rsync -avh --inplace --partial --delete --progress /mnt/nvme/ /mnt/pool/backup/
echo "Installing prerequisites..."
sudo apt install -y pv
echo "Deleting existing backups..."
sudo zfs destroy pool/backup@backup
sudo zfs destroy nvme/data@backup
echo "Creating snapshot..."
sudo zfs snapshot -r nvme/data@backup
echo "Sending snapshot from nvme/data to pool/backup..."
sudo zfs send -vR nvme/data@backup | pv | sudo zfs receive -vF pool/backup
echo "Deleting data backup"
sudo zfs destroy nvme/data@backup
几乎同时,脚本在问号处运行结束了,因此第二次运行 zfs list -t snapshot 时,nvme 的快照已经被删除了,而 pool 的快照已经被创建了。
而第二个问题,我们很快在试验室里运行上述脚本就得到了完全相同的结论:
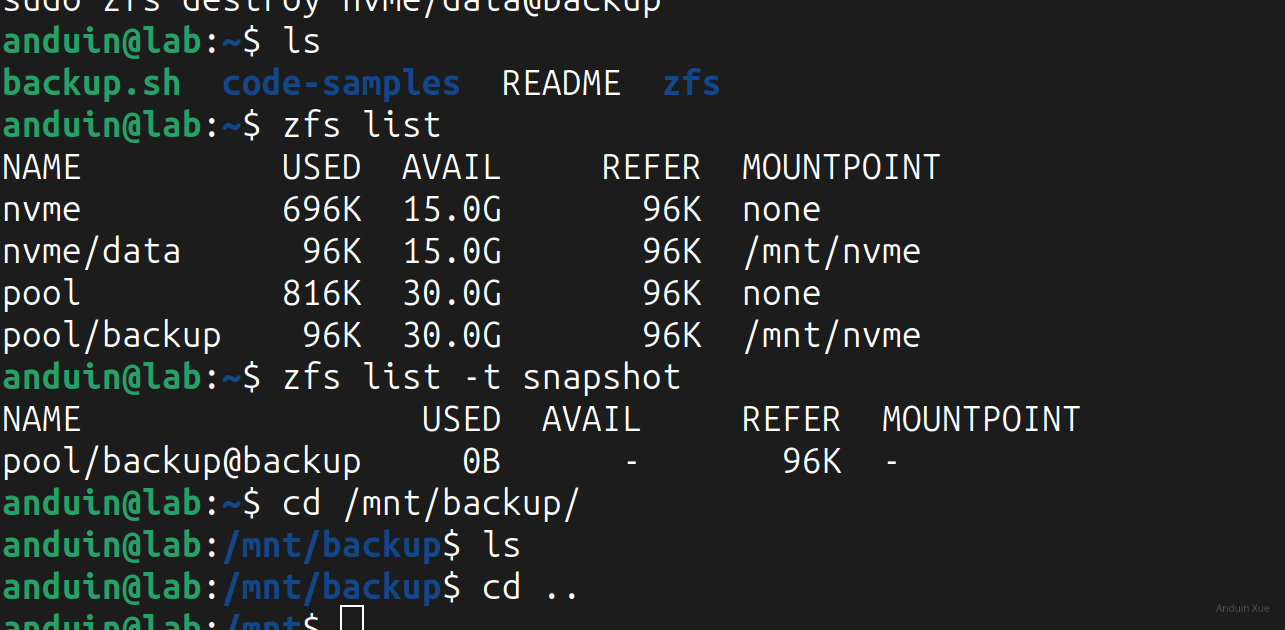
只要运行上述脚本,一定会导致两个 dataset 的 MOUNTPOINT 是同一个目录。而在正常操作下,ZFS 是不允许两个 dataset 挂载到同一个目录的。
这可能是我们没有正确理解 zfs send 和 receive 的用途。在我们的理解中,zfs send 和 receive 是用来将一个 snapshot 复制到另一个 dataset 的。但是实际上,它很可能会保持 MOUNTPOINT 的一致性,因此,zfs send 和 receive 就会将 MOUNTPOINT 也复制过去,然后导致两个 dataset 的数据重叠。
另外,我们也重新理解了 zfs list:它展示的 MOUNTPOINT 只是一个dataset的metadata,和一个dataset是否被mount无关。因此,判断一个目录是否是ZFS Dataset不应该基于 zfs list,而是应该基于 df -Th。正是因为这个关键失误导致了在调查时出现了障碍。
教训
这次事故给我们带来了非常大的教训。首先,我们应该在试验环境中测试脚本,而不是直接在生产环境中运行。只有在对操作非常有把握,运行的脚本已经广泛测试之后才应当在生产环境执行。
其次,我们应该对脚本的运行结果进行更多的检查和监控。我们将考虑针对crontab、tmux建设更多的基于Prometheus的监控和告警系统。
当然,我们也决定对老的备份脚本进行改造,并且新的脚本在试验室中被反复验证,再在生产服务器上逐行执行。
改进
新的脚本我们重新探讨了备份的思路:
我们备份的目标其实并吧是将快照发送过去,而是我们需要文件在磁盘损坏后仍然可以访问。因此我们决定组合使用snapshot send和rollback。
在rollback后,我们直接mount zfs的dataset即可看到发过去的snapshot中的文件。而此时,snapshot已经不再重要,这里可以直接删除snapshot。(这里不会影响安全性,因为发过去的文件是归档文件,它不会被修改,也不会和snapshot有区别)
当然,为了避免出现上述问题,我们干脆在备份期间将整个dataset unmount掉。而一个目录是否被mount,这并不是ZFS的问题,而是Linux本身的设计哲学:设备会被mount变成目录,已经导致了判断一个目录是否属于一个设备就比Windows困难。在Windows上,盘坏、盘掉都会直接粗暴的以D盘找不到的错误直接展示,而在Linux的世界,这里这需要万分小心。当然,unmount掉然后发送快照自然可以规避这些问题。
最终的备份脚本是:
#sudo rsync -avh --exclude "*.vswp" --inplace --partial --delete --progress /mnt/nvme/ /mnt/pool/backup/
echo "Deleting exising backups..."
sudo zfs destroy pool/backup@backup
sudo zfs destroy nvme/data@backup
echo "Creating snapshot..."
sudo touch /mnt/nvme/$(date +"%Y-%m-%d-%H-%M-%S")
sudo zfs snapshot nvme/data@backup
echo "Unmounting backup..."
sudo zfs unmount pool/backup
echo "Sending snapshot from nvme/data to pool/backup..."
sudo bash -c 'zfs send -v nvme/data@backup | zfs receive -vF pool/backup'
echo "Reseting workspace to snapshot..."
sudo zfs rollback pool/backup@backup
sudo zfs mount pool/backup
echo "Deleting snapshots..."
sudo zfs destroy nvme/data@backup
sudo zfs destroy pool/backup@backup
上述脚本会删除所有快照(这是安全的,因为备份好的文件就在 /mnt/backup 下),然后对数据打一个标签,随后快照,再将整个快照发送到备份pool,随后立刻rollback,再mount,即可让快照里的文件呈现为目录,随后删除快照(这也是安全的,因为备份好的文件也已经在 /mnt/backup 下了)。
实际我们在实验室里测试多次,并且在生产环境备份数次,其工作良好,任何情况下数据至少都有两份:
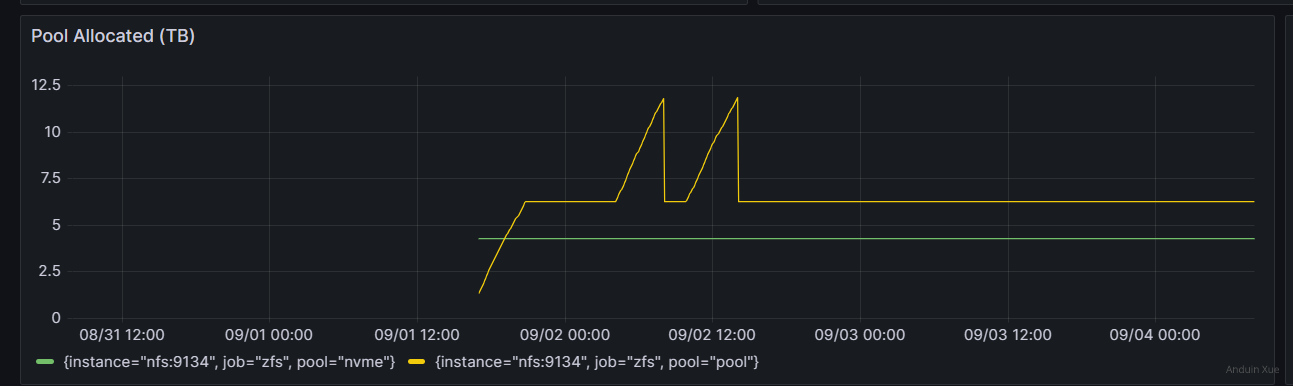
如图所示,绿线是生产的pool,黄线是备份的pool。
此次事故暴露出生产环境脚本操作中的深层认知盲区,值得在系统设计层面进行反思。ZFS快照传输过程中的挂载点继承机制,本质上是将元数据状态同步到目标数据集,这种设计初衷是为跨存储迁移保留完整环境配置,却在本案例中触发了违反Linux挂载规则的致命冲突。这提示我们在使用跨池快照克隆时,必须显式重置关键元数据属性,而非依赖默认行为。
从系统工程角度看,该事故揭示了"隐式依赖"的破坏性——NFS挂载点与ZFS数据集的耦合关系未被显式声明,导致状态变更时的连锁反应难以预料。改进后的方案通过卸载-传输-回滚的显式操作序列,将隐式依赖转化为可验证的显式流程,这种设计模式值得在所有涉及状态变更的自动化操作中推广。
值得关注的是,新脚本采用的"快照即备份"策略,实质上是将ZFS的版本控制能力转化为数据保护机制。通过rollback操作实现的原子性切换,既保证了数据一致性,又规避了传统备份中文件系统状态不一致的风险。这种利用底层存储特性构建可靠备份方案的思路,为同类场景提供了有价值的参考。
事故中暴露的工具链短板也值得深思:ZFS的挂载点管理缺乏自动冲突检测机制,而Linux系统层面也未能对多数据集挂载冲突提供有效防护。这提示我们需要在监控体系中增加对关键系统状态的拓扑检测,例如通过实时跟踪挂载点与数据集的映射关系,提前预警潜在的配置冲突。
这篇文章通过一次ZFS备份故障的详细经历,分享了宝贵的经验教训,并提出了切实可行的改进方案,值得深入探讨和学习。
文章的核心在于团队如何从故障中发现、分析并解决问题。整个过程展现了快速响应和细致排查的能力。特别是在处理复杂存储问题时,对命令的理解和工具的选择显得尤为重要。通过
df -Th而非zfs list来确认挂载点这一细节,提醒我们日常工作中要不断学习工具的使用方法。文章中提到的几点教训都非常具有参考价值:
zfs send/receive等命令的深入理解能够避免低级错误。文章提到的改进措施也非常到位:
如果我有幸参与讨论,我会建议作者进一步考虑以下几点:
总体来说,这篇文章不仅记录了一次故障排除的过程,更展现了团队在问题面前的成长与进步。通过分享这些经验教训,相信能够帮助更多人在使用ZFS和设计备份策略时少走弯路。
安度因老师的思维逻辑和复盘真厉害
6666666666
这篇博文详细地记录了作者在处理服务器事故的过程,以及他的思考和解决方案。文章的优点在于详细的步骤记录和清晰的问题分析,这使得读者能够很好地理解问题的发生、发展和解决过程。在此过程中,作者的专业知识和经验得到了很好的体现。
文章的核心理念是在面对复杂问题时,需要冷静分析,逐步排查,并且通过实验和测试来验证自己的假设。这种理念值得赞赏和学习。
然而,文章的改进空间主要在于对问题的预防措施和长期解决方案的探讨上。例如,作者提到应该在试验环境中测试脚本,而不是直接在生产环境中运行。这是一个很好的建议,但是具体如何设置和使用试验环境,以及如何确保试验环境和生产环境的一致性等问题,文章中并没有详细讨论。这些都是在实际操作中非常重要的问题。
此外,文章中也没有讨论如何防止类似问题的再次发生。虽然作者提到了他们将建设更多的基于Prometheus的监控和告警系统,但是具体如何建设,以及如何利用这些系统来防止问题的发生,也是值得深入探讨的问题。
总的来说,这篇文章是一篇很好的技术博客,既展示了作者的专业知识和经验,也提供了一种面对复杂问题的思考和解决方法。但是在预防措施和长期解决方案的探讨上,还有很大的改进空间。